引言
从本篇文章开始,我们将介绍 Java AQS 的实现方式,本文先介绍 AQS 的内部数据是如何组织的,后面的文章中再分别介绍 AQS 的各个部门实现。
AQS
通过前面的介绍,大家一定看出来了,上述的各种类型的锁和一些线程控制接口(CountDownLatch 等),最终都是通过 AQS 来实现的,不同之处只在于 tryAcquire 等抽象函数如何实现。从这个角度来看,AQS(AbstractQueuedSynchronizer) 这个基类设计的真的很不错,能够包容各种同步控制方案,并提供了必须的下层依赖:比如阻塞,队列等。接下来我们就来揭开它神秘的面纱。
内部数据
AQS 顾名思义,就是通过队列来组织修改互斥资源的请求。当这个资源空闲时间,那么修改请求可以直接进行,而当这个资源处于锁定状态时,就需要等待,AQS 会将所有等待的请求维护在一个类似于 CLH 的队列中。CLH:Craig、Landin and Hagersten队列,是单向链表,AQS中的队列是CLH变体的虚拟双向队列(FIFO),AQS是通过将每条请求共享资源的线程封装成一个节点来实现锁的分配。主要原理图如下:
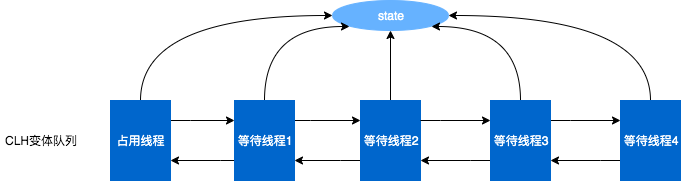
图中的 state 是一个用 volatile 修饰的 int 变量,它的使用都是通过 CAS 来进行的,而 FIFO 队列完成请求排队的工作,队列的操作也是通过 CAS 来进行的,正因如此该队列的操作才能达到理想的性能要求。
通过 CAS 修改 state 比较容易,大家应该都能理解,但是如果要通过 CAS 维护一个双向队列要怎么做呢?这里我们看一下 AQS 中 CLH 队列的实现。在 AQS 中有两个指针一个指针指向了队列头,一个指向了队列尾。它们都是懒初始化的,也就是说最初都为null。
- /**
- * Head of the wait queue, lazily initialized. Except for
- * initialization, it is modified only via method setHead. Note:
- * If head exists, its waitStatus is guaranteed not to be
- * CANCELLED.
- */
- private transient volatile Node head;
- /**
- * Tail of the wait queue, lazily initialized. Modified only via
- * method enq to add new wait node.
- */
- private transient volatile Node tail;
队列中的每个节点,都是一个 Node 实例,该实例的第一个关键字段是 waitState,它表述了当前节点所处的状态,通过 CAS 进行修改:
- SIGNAL:表示当前节点承担唤醒后继节点的责任
- CANCELLED:表示当前节点已经超时或者被打断
- CONDITION:表示当前节点正在 Condition 上等待(通过锁可以创建 Condition 对象)
- PROPAGATE:只会设置在 head 节点上,用于表明释放共享锁时,需要将这个行为传播到其他节点上,这个我们稍后详细介绍。
- static final class Node {
- /** Marker to indicate a node is waiting in shared mode */
- static final Node SHARED = new Node();
- /** Marker to indicate a node is waiting in exclusive mode */
- static final Node EXCLUSIVE = null;
- /** waitStatus value to indicate thread has cancelled */
- static final int CANCELLED = 1;
- /** waitStatus value to indicate successor's thread needs unparking */
- static final int SIGNAL = –1;
- /** waitStatus value to indicate thread is waiting on condition */
- static final int CONDITION = –2;
- /**
- * waitStatus value to indicate the next acquireShared should
- * unconditionally propagate
- */
- static final int PROPAGATE = –3;
- /**
- * Status field, taking on only the values:
- * SIGNAL: The successor of this node is (or will soon be)
- * blocked (via park), so the current node must
- * unpark its successor when it releases or
- * cancels. To avoid races, acquire methods must
- * first indicate they need a signal,
- * then retry the atomic acquire, and then,
- * on failure, block.
- * CANCELLED: This node is cancelled due to timeout or interrupt.
- * Nodes never leave this state. In particular,
- * a thread with cancelled node never again blocks.
- * CONDITION: This node is currently on a condition queue.
- * It will not be used as a sync queue node
- * until transferred, at which time the status
- * will be set to 0. (Use of this value here has
- * nothing to do with the other uses of the
- * field, but simplifies mechanics.)
- * PROPAGATE: A releaseShared should be propagated to other
- * nodes. This is set (for head node only) in
- * doReleaseShared to ensure propagation
- * continues, even if other operations have
- * since intervened.
- * 0: None of the above
- *
- * The values are arranged numerically to simplify use.
- * Non-negative values mean that a node doesn't need to
- * signal. So, most code doesn't need to check for particular
- * values, just for sign.
- *
- * The field is initialized to 0 for normal sync nodes, and
- * CONDITION for condition nodes. It is modified using CAS
- * (or when possible, unconditional volatile writes).
- */
- volatile int waitStatus;
- /**
- * Link to predecessor node that current node/thread relies on
- * for checking waitStatus. Assigned during enqueuing, and nulled
- * out (for sake of GC) only upon dequeuing. Also, upon
- * cancellation of a predecessor, we short-circuit while
- * finding a non-cancelled one, which will always exist
- * because the head node is never cancelled: A node becomes
- * head only as a result of successful acquire. A
- * cancelled thread never succeeds in acquiring, and a thread only
- * cancels itself, not any other node.
- */
- volatile Node prev;
- /**
- * Link to the successor node that the current node/thread
- * unparks upon release. Assigned during enqueuing, adjusted
- * when bypassing cancelled predecessors, and nulled out (for
- * sake of GC) when dequeued. The enq operation does not
- * assign next field of a predecessor until after attachment,
- * so seeing a null next field does not necessarily mean that
- * node is at end of queue. However, if a next field appears
- * to be null, we can scan prev's from the tail to
- * double-check. The next field of cancelled nodes is set to
- * point to the node itself instead of null, to make life
- * easier for isOnSyncQueue.
- */
- volatile Node next;
- /**
- * The thread that enqueued this node. Initialized on
- * construction and nulled out after use.
- */
- volatile Thread thread;
- /**
- * Link to next node waiting on condition, or the special
- * value SHARED. Because condition queues are accessed only
- * when holding in exclusive mode, we just need a simple
- * linked queue to hold nodes while they are waiting on
- * conditions. They are then transferred to the queue to
- * re-acquire. And because conditions can only be exclusive,
- * we save a field by using special value to indicate shared
- * mode.
- */
- Node nextWaiter;
- /**
- * Returns true if node is waiting in shared mode.
- */
- final boolean isShared() {
- return nextWaiter == SHARED;
- }
- //…
- }
因为是双向队列,所以 Node 实例中势必有 prev 和 next 指针,此外 Node 中还会保存与其对应的线程。最后是 nextWaiter,当一个节点对应了共享请求时,nextWaiter 指向了 Node. SHARED 而当一个节点是排他请求时,nextWaiter 默认指向了 Node. EXCLUSIVE 也就是 null。我们知道 AQS 也提供了 Condition 功能,该功能就是通过 nextWaiter 来维护在 Condition 上等待的线程。也就是说这里的 nextWaiter 在锁的实现部分中,扮演者共享锁和排它锁的标志位,而在条件等待队列中,充当链表的 next 指针。
同步队列
接下来,我们由最常见的入队操作出发,介绍 AQS 框架的实现与使用。从下面的代码中可以看到入队操作支持两种模式,一种是排他模式,一种是共享模式,分别对应了排它锁场景和共享锁场景。
- 当任意一种请求,要入队时,先会构建一个 Node 实例,然后获取当前 AQS 队列的尾结点,如果尾结点为空,就是说队列还没初始化,初始化过程在后面 enq 函数中实现
- 这里我们先看初始化之后的情况,即 tail != null,先将当前 Node 的前向指针 prev 更新,然后通过 CAS 将尾结点修改为当前 Node,修改成功时,再更新前一个节点的后向指针 next,因为只有修改尾指针过程是原子的,所以这里会出现新插入一个节点时,之前的尾节点 previousTail 的 next 指针为null的情况,也就是说会存在短暂的正向指针和反向指针不同步的情况,不过在后面的介绍中,你会发现 AQS 很完备地避开了这种不同步带来的风险(通过从后往前遍历)
- 如果上述操作成功,则当前线程已经进入同步队列,否则,可能存在多个线程的竞争,其他线程设置尾结点成功了,而当前线程失败了,这时候会和尾结点未初始化一样进入 enq 函数中。
- /**
- * Creates and enqueues node for current thread and given mode.
- *
- * @param mode Node.EXCLUSIVE for exclusive, Node.SHARED for shared
- * @return the new node
- */
- private Node addWaiter(Node mode) {
- Node node = new Node(Thread.currentThread(), mode);
- // Try the fast path of enq; backup to full enq on failure
- Node pred = tail;
- if (pred != null) {
- // 已经进行了初始化
- node.prev = pred;
- // CAS 修改尾节点
- if (compareAndSetTail(pred, node)) {
- // 成功之后再修改后向指针
- pred.next = node;
- return node;
- }
- }
- // 循环 CAS 过程和初始化过程
- enq(node);
- return node;
- }
正常通过 CAS 修改数据都会在一个循环中进行,而这里的 addWaiter 只是在一个 if 中进行,这是为什么呢?实际上,大家看到的 addWaiter 的这部分 CAS 过程是一个快速执行线,在没有竞争时,这种方式能省略不少判断过程。当发生竞争时,会进入 enq 函数中,那里才是循环 CAS 的地方。
- 整个 enq 的工作在一个循环中进行
- 先会检查是否未进行初始化,是的话,就设置一个虚拟节点 Node 作为 head 和 tail,也就是说同步队列的第一个节点并不保存实际数据,只是一个保存指针的地方
- 初始化完成后,通过 CAS 修改尾节点,直到修改成功为止,最后修复后向指针
- /**
- * Inserts node into queue, initializing if necessary. See picture above.
- * @param node the node to insert
- * @return node's predecessor
- */
- private Node enq(final Node node) {
- for (;;) {// 在一个循环中进行 CAS 操作
- Node t = tail;
- if (t == null) { // Must initialize
- if (compareAndSetHead(new Node()))
- tail = head;
- } else {
- node.prev = t;
- // CAS 修改尾节点
- if (compareAndSetTail(t, node)) {
- // 成功之后再修改后向指针
- t.next = node;
- return t;
- }
- }
以上就是通过AQS实现数据组织的详细内容,更多关于AQS数据组织的资料请关注快网idc其它相关文章!
原文链接:https://blog.csdn.net/BeiKeJieDeLiuLangMao/article/details/115269300