

背景知识
同步、异步、阻塞、非阻塞
首先,这几个概念非常容易搞混淆,但nio中又有涉及,所以总结一下。
同步:api调用返回时调用者就知道操作的结果如何了(实际读取/写入了多少字节)。
异步:相对于同步,api调用返回时调用者不知道操作的结果,后面才会回调通知结果。
阻塞:当无数据可读,或者不能写入所有数据时,挂起当前线程等待。
非阻塞:读取时,可以读多少数据就读多少然后返回,写入时,可以写入多少数据就写入多少然后返回。
对于i/o操作,根据oracle官网的文档,同步异步的划分标准是“调用者是否需要等待i/o操作完成”,这个“等待i/o操作完成”的意思不是指一定要读取到数据或者说写入所有数据,而是指真正进行i/o操作时,比如数据在tcp/ip协议栈缓冲区和jvm缓冲区之间传输的这段时间,调用者是否要等待。
所以,我们常用的read()和write()方法都是同步i/o,同步i/o又分为阻塞和非阻塞两种模式,如果是非阻塞模式,检测到无数据可读时,直接就返回了,并没有真正执行i/o操作。
总结就是,java中实际上只有同步阻塞i/o、同步非阻塞i/o与异步i/o三种机制,我们下文所说的是前两种,jdk1.7才开始引入异步i/o,那称之为nio.2。
传统io
我们知道,一个新技术的出现总是伴随着改进和提升,javanio的出现亦如此。
传统i/o是阻塞式i/o,主要问题是系统资源的浪费。比如我们为了读取一个tcp连接的数据,调用inputstream的read()方法,这会使当前线程被挂起,直到有数据到达才被唤醒,那该线程在数据到达这段时间内,占用着内存资源(存储线程栈)却无所作为,也就是俗话说的占着茅坑不拉屎,为了读取其他连接的数据,我们不得不启动另外的线程。在并发连接数量不多的时候,这可能没什么问题,然而当连接数量达到一定规模,内存资源会被大量线程消耗殆尽。另一方面,线程切换需要更改处理器的状态,比如程序计数器、寄存器的值,因此非常频繁的在大量线程之间切换,同样是一种资源浪费。
随着技术的发展,现代操作系统提供了新的i/o机制,可以避免这种资源浪费。基于此,诞生了javanio,nio的代表性特征就是非阻塞i/o。紧接着我们发现,简单的使用非阻塞i/o并不能解决问题,因为在非阻塞模式下,read()方法在没有读取到数据时就会立即返回,不知道数据何时到达的我们,只能不停的调用read()方法进行重试,这显然太浪费cpu资源了,从下文可以知道,selector组件正是为解决此问题而生。
1.channel
概念
javanio中的所有i/o操作都基于channel对象,就像流操作都要基于stream对象一样,因此很有必要先了解channel是什么。以下内容摘自jdk1.8的文档
achannelrepresentsanopenconnectiontoanentitysuchasahardwaredevice,afile,anetworksocket,oraprogramcomponentthatiscapableofperformingoneormoredistincti/ooperations,forexamplereadingorwriting.
从上述内容可知,一个channel(通道)代表和某一实体的连接,这个实体可以是文件、网络套接字等。也就是说,通道是javanio提供的一座桥梁,用于我们的程序和操作系统底层i/o服务进行交互。
通道是一种很基本很抽象的描述,和不同的i/o服务交互,执行不同的i/o操作,实现不一样,因此具体的有filechannel、socketchannel等。
通道使用起来跟stream比较像,可以读取数据到buffer中,也可以把buffer中的数据写入通道。
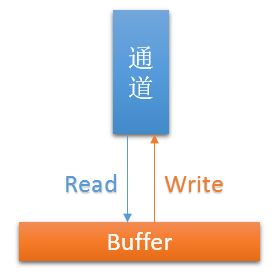
当然,也有区别,主要体现在如下两点:
一个通道,既可以读又可以写,而一个stream是单向的(所以分inputstream和outputstream)
通道有非阻塞i/o模式
实现
javanio中最常用的通道实现是如下几个,可以看出跟传统的i/o操作类是一一对应的。
filechannel:读写文件
datagramchannel:udp协议网络通信
socketchannel:tcp协议网络通信
serversocketchannel:监听tcp连接
2.buffer
nio中所使用的缓冲区不是一个简单的byte数组,而是封装过的buffer类,通过它提供的api,我们可以灵活的操纵数据,下面细细道来。
与java基本类型相对应,nio提供了多种buffer类型,如bytebuffer、charbuffer、intbuffer等,区别就是读写缓冲区时的单位长度不一样(以对应类型的变量为单位进行读写)。
buffer中有3个很重要的变量,它们是理解buffer工作机制的关键,分别是
capacity(总容量)
position(指针当前位置)
limit(读/写边界位置)
buffer的工作方式跟c语言里的字符数组非常的像,类比一下,capacity就是数组的总长度,position就是我们读/写字符的下标变量,limit就是结束符的位置。buffer初始时3个变量的情况如下图
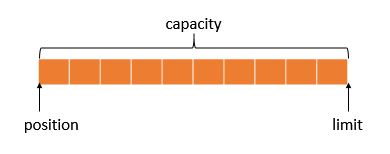
在对buffer进行读/写的过程中,position会往后移动,而limit就是position移动的边界。由此不难想象,在对buffer进行写入操作时,limit应当设置为capacity的大小,而对buffer进行读取操作时,limit应当设置为数据的实际结束位置。(注意:将buffer数据写入通道是buffer读取操作,从通道读取数据到buffer是buffer写入操作)
在对buffer进行读/写操作前,我们可以调用buffer类提供的一些辅助方法来正确设置position和limit的值,主要有如下几个
flip():设置limit为position的值,然后position置为0。对buffer进行读取操作前调用。
rewind():仅仅将position置0。一般是在重新读取buffer数据前调用,比如要读取同一个buffer的数据写入多个通道时会用到。
clear():回到初始状态,即limit等于capacity,position置0。重新对buffer进行写入操作前调用。
compact():将未读取完的数据(position与limit之间的数据)移动到缓冲区开头,并将position设置为这段数据末尾的下一个位置。其实就等价于重新向缓冲区中写入了这么一段数据。
然后,看一个实例,使用filechannel读写文本文件,通过这个例子验证通道可读可写的特性以及buffer的基本用法(注意filechannel不能设置为非阻塞模式)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
filechannel channel = new randomaccessfile("test.txt", "rw").getchannel();
channel.position(channel.size());
// 移动文件指针到末尾(追加写入)
bytebuffer bytebuffer = bytebuffer.allocate(20);
// 数据写入buffer
bytebuffer.put("你好,世界!\\n".getbytes(standardcharsets.utf_8));
// buffer -> channel
bytebuffer.flip();
while (bytebuffer.hasremaining()) {
channel.write(bytebuffer);
}
channel.position(0);
// 移动文件指针到开头(从头读取)
charbuffer charbuffer = charbuffer.allocate(10);
charsetdecoder decoder = standardcharsets.utf_8.newdecoder();
// 读出所有数据
bytebuffer.clear();
while (channel.read(bytebuffer) != -1 || bytebuffer.position() > 0) {
bytebuffer.flip();
// 使用utf-8解码器解码
charbuffer.clear();
decoder.decode(bytebuffer, charbuffer, false);
system.out.print(charbuffer.flip().tostring());
bytebuffer.compact();
// 数据可能有剩余
}
channel.close();
|
这个例子中使用了两个buffer,其中 bytebuffer 作为通道读写的数据缓冲区,charbuffer 用于存储解码后的字符。clear() 和 flip() 的用法正如上文所述,需要注意的是最后那个 compact() 方法,即使 charbuffer 的大小完全足以容纳 bytebuffer 解码后的数据,这个 compact() 也必不可少,这是因为常用中文字符的utf-8编码占3个字节,因此有很大概率出现在中间截断的情况,请看下图:
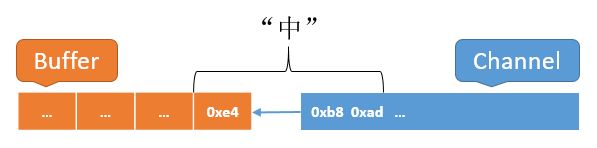
当 decoder 读取到缓冲区末尾的 0xe4 时,无法将其映射到一个 unicode,decode()方法第三个参数 false 的作用就是让 decoder 把无法映射的字节及其后面的数据都视作附加数据,因此 decode() 方法会在此处停止,并且 position 会回退到 0xe4 的位置。如此一来, 缓冲区中就遗留了“中”字编码的第一个字节,必须将其 compact 到前面,以正确的和后序数据拼接起来。关于字符编码,大家可以参阅《ansi,unicode,bmp,utf等编码概念实例讲解》
btw,例子中的charsetdecoder也是javanio的一个新特性,所以大家应该发现了一点哈,nio的操作是面向缓冲区的(传统i/o是面向流的)。
至此,我们了解了channel与buffer的基本用法。接下来要说的是让一个线程管理多个channel的重要组件。
3.selector
selector是什么
selector(选择器)是一个特殊的组件,用于采集各个通道的状态(或者说事件)。我们先将通道注册到选择器,并设置好关心的事件,然后就可以通过调用select()方法,静静地等待事件发生。
通道有如下4个事件可供我们监听:
accept:有可以接受的连接
connect:连接成功
read:有数据可读
write:可以写入数据了
为什么要用selector
前文说了,如果用阻塞i/o,需要多线程(浪费内存),如果用非阻塞i/o,需要不断重试(耗费cpu)。selector的出现解决了这尴尬的问题,非阻塞模式下,通过selector,我们的线程只为已就绪的通道工作,不用盲目的重试了。比如,当所有通道都没有数据到达时,也就没有read事件发生,我们的线程会在select()方法处被挂起,从而让出了cpu资源。
使用方法
如下所示,创建一个selector,并注册一个channel。
注意:要将channel注册到selector,首先需要将channel设置为非阻塞模式,否则会抛异常。
|
1
2
3
|
selector selector = selector.open();
channel.configureblocking(false);
selectionkey key = channel.register(selector, selectionkey.op_read);
|
register()方法的第二个参数名叫“interest set”,也就是你所关心的事件集合。如果你关心多个事件,用一个“按位或运算符”分隔,比如
|
1
|
selectionkey.op_read | selectionkey.op_write
|
这种写法一点都不陌生,支持位运算的编程语言里都这么玩,用一个整型变量可以标识多种状态,它是怎么做到的呢,其实很简单,举个例子,首先预定义一些常量,它们的值(二进制)如下

可以发现,它们值为1的位都是错开的,因此对它们进行按位或运算之后得出的值就没有二义性,可以反推出是由哪些变量运算而来。怎么判断呢,没错,就是“按位与”运算。比如,现在有一个状态集合变量值为0011,我们只需要判断“0011&op_read”的值是1还是0就能确定集合是否包含op_read状态。
然后,注意register()方法返回了一个selectionkey的对象,这个对象包含了本次注册的信息,我们也可以通过它修改注册信息。从下面完整的例子中可以看到,select()之后,我们也是通过获取一个selectionkey的集合来获取到那些状态就绪了的通道。
一个完整实例
概念和理论的东西阐述完了(其实写到这里,我发现没写出多少东西,好尴尬(⊙ˍ⊙)),看一个完整的例子吧。
这个例子使用javanio实现了一个单线程的服务端,功能很简单,监听客户端连接,当连接建立后,读取客户端的消息,并向客户端响应一条消息。
需要注意的是,我用字符‘\\0′(一个值为0的字节)来标识消息结束。
单线程server
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
public class nioserver {
public static void main(string[] args) throws ioexception {
// 创建一个selector
selector selector = selector.open();
// 初始化tcp连接监听通道
serversocketchannel listenchannel = serversocketchannel.open();
listenchannel.bind(new inetsocketaddress(9999));
listenchannel.configureblocking(false);
// 注册到selector(监听其accept事件)
listenchannel.register(selector, selectionkey.op_accept);
// 创建一个缓冲区
bytebuffer buffer = bytebuffer.allocate(100);
while (true) {
selector.select();
//阻塞,直到有监听的事件发生
iterator<selectionkey> keyiter = selector.selectedkeys().iterator();
// 通过迭代器依次访问select出来的channel事件
while (keyiter.hasnext()) {
selectionkey key = keyiter.next();
if (key.isacceptable()) {
// 有连接可以接受
socketchannel channel = ((serversocketchannel) key.channel()).accept();
channel.configureblocking(false);
channel.register(selector, selectionkey.op_read);
system.out.println("与【" + channel.getremoteaddress() + "】建立了连接!");
} else if (key.isreadable()) {
// 有数据可以读取
buffer.clear();
// 读取到流末尾说明tcp连接已断开,
// 因此需要关闭通道或者取消监听read事件
// 否则会无限循环
if (((socketchannel) key.channel()).read(buffer) == -1) {
key.channel().close();
continue;
}
// 按字节遍历数据
buffer.flip();
while (buffer.hasremaining()) {
byte b = buffer.get();
if (b == 0) {
// 客户端消息末尾的\\0
system.out.println();
// 响应客户端
buffer.clear();
buffer.put("hello, client!\\0".getbytes());
buffer.flip();
while (buffer.hasremaining()) {
((socketchannel) key.channel()).write(buffer);
}
} else {
system.out.print((char) b);
}
}
}
// 已经处理的事件一定要手动移除
keyiter.remove();
}
}
}
}
|
client
这个客户端纯粹测试用,为了看起来不那么费劲,就用传统的写法了,代码很简短。
要严谨一点测试的话,应该并发运行大量client,统计服务端的响应时间,而且连接建立后不要立刻发送数据,这样才能发挥出服务端非阻塞i/o的优势。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public class client {
public static void main(string[] args) throws exception {
socket socket = new socket("localhost", 9999);
inputstream is = socket.getinputstream();
outputstream os = socket.getoutputstream();
// 先向服务端发送数据
os.write("hello, server!\\0".getbytes());
// 读取服务端发来的数据
int b;
while ((b = is.read()) != 0) {
system.out.print((char) b);
}
system.out.println();
socket.close();
}
}
|
总结
以上就是本文关于快速了解java中nio核心组件的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关内容,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
原文链接:http://www.php.cn/java-article-374697.html

相关文章


- 64M VPS建站:是否适合初学者操作和管理? 2025-06-10
- ASP.NET自助建站系统中的用户注册和登录功能定制方法 2025-06-10
- ASP.NET自助建站系统的域名绑定与解析教程 2025-06-10
- 个人服务器网站搭建:如何选择合适的服务器提供商? 2025-06-10
- ASP.NET自助建站系统中如何实现多语言支持? 2025-06-10



