为什么使用“小偷程序”?
远程抓取文章资讯或商品信息是很多企业要求程序员实现的功能,也就是俗说的小偷程序。其最主要的优点是:解决了公司网编繁重的工作,大大提高了效率。只需要一运行就能快速的抓取别人网站的信息。
“小偷程序”在哪里运行?
“小偷程序” 应该在 windows 下的 dos或 linux 下通过 php 命令运行为最佳,因为,网页运行会超时。
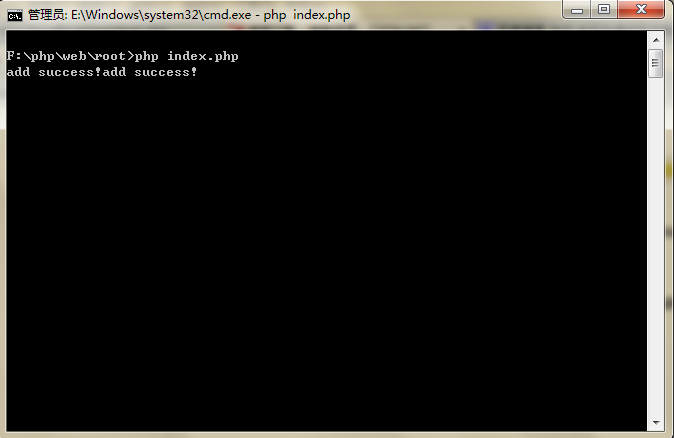
比如图(windows 下 dos 为例):
“小偷程序”的实现
这里主要通过一个实例来讲解,我们来抓取下“华强电子网”的资讯信息,请先看观察这个链接 http://www.hqew.com/info-c10.html,当您打开这个页面的时候发现这个页面会发现一些现象:
1、资讯列表有 500 页(2012-01-03);
2、每页的 url 链接都有规律,比如:第1页为http://www.hqew.com/info-c10-1.html;第2页为http://www.hqew.com/info-c10-2.html;……第500页为http://www.hqew.com/info-c10-500.html;
3、由第二点就可以知道,“华强电子网” 的资讯是伪静态或者是生成的静态页面
其实,基本上大部分的网站都有这样的规律,比如:中关村在线、慧聪网、新浪、淘宝……。
这样,我们可以通过这样的思路来实现页面内容的抓取:
1、先获取文章列表页内容;
2、根据文章列表页内容循环获取文章的 url 地址;
3、根据文章的 url 地址获取文章的详细内容
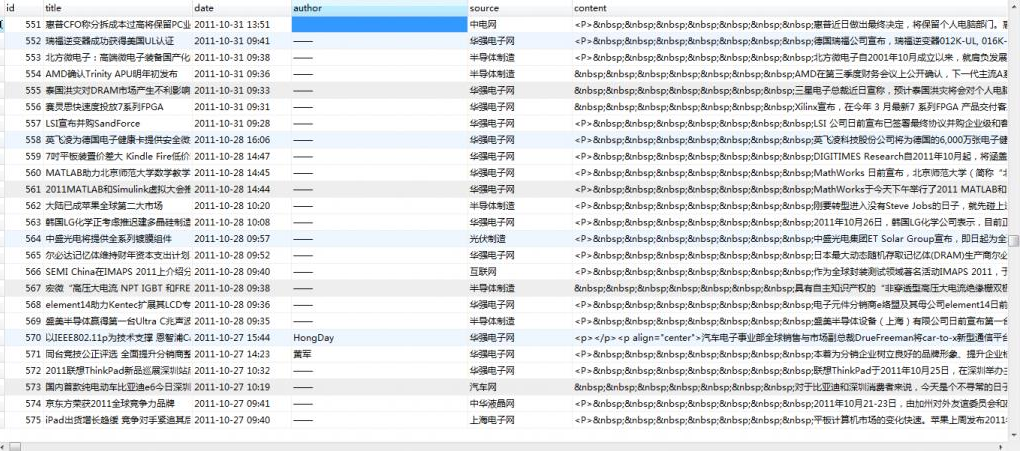
这里,我们主要抓取资讯页里面的:标题(title)、发布如期(date)、作者(author)、来源(source)、内容(content)
“华强电子网”资讯抓取
首先,先建数据表结构,如下所示:
|
1
2
3
4
5
6
7
8
|
create table `article`.`article` (
`id` mediumint( 8 ) unsigned not null auto_increment primary key ,
`title` varchar( 255 ) character set utf8 collate utf8_general_ci not null ,
`date` varchar( 50 ) not null ,
`author` varchar( 100 ) character set utf8 collate utf8_general_ci not null ,
`source` varchar( 100 ) character set utf8 collate utf8_general_ci not null ,
`content` text not null
) engine = myisam character set utf8 collate utf8_general_ci;
|
抓取程序:
- <?php
- /**
- *抓取“华强电子网”资讯程序
- *authorlee.
- *lastmodify$date:2012-1-315:39:35$
- */
- header('content-type:text/html;charset=utf-8');
- $mysqli=newmysqli('localhost','root','1715544','article');#数据库连接,请手动修改您自己的数据库信息
- $mysqli->set_charset('utf8');#设置数据库编码
- functiondata($url){
- global$mysqli;
- $result=file_get_contents($url);#$result获取url链接内容(注意:这里是文章列表链接)
- $pattern='/<li><spanclass="box_r">.+</span><ahref="([^"]+)"title=".+">.+</a></li>/usi';#取得文章url的匹配正则
- preg_match_all($pattern,$result,$arr);#把文章列表url分配给数组$arr(二维数组)
- foreach($arr[1]as$val){
- $val='http://www.hqew.com'.$val;#真实文章url地址
- $re=file_get_contents($val);#$re为文章url的内容
- $pa='/<divid="article">s+<h1>(.+)</h1>s+<pid="article_extinfo">s+发布:s+(.+)s+|s+作者:s+(.+)s+|s+来源:s+(.*?)s+<spanstyle="display:none">.+<divid="article_body">s*(.+)s+</div>s+</div><!–articleend–>/usi';#取得文章内容的正则
- preg_match_all($pa,$re,$array);#把取到的内容分配到数组$array
- $content=trim($array[5][0]);
- $con=array(
- 'title'=>mysqlstring($array[1][0]),
- 'date'=>mysqlstring($array[2][0]),
- 'author'=>mysqlstring(stripauthortag($array[3][0])),
- 'source'=>mysqlstring($array[4][0]),
- 'content'=>mysqlstring(stripcontenttag($content))
- );
- $sql="insertintoarticle(title,date,author,source,content)values('{$con['title']}','{$con['date']}','{$con['author']}','{$con['source']}','{$con['content']}')";
- $row=$mysqli->query($sql);#添加到数据库
- if($row){
- echo'addsuccess!';
- }else{
- echo'addfailed!';
- }
- }
- }
- /**
- *stripofficetag($v)对文章内容进行过滤,比如:去掉文章中的链接,过滤掉没用的html标签……
- *@paramstring$v
- *@returnstring
- */
- functionstripcontenttag($v){
- $v=str_replace('<p></p>','',$v);
- $v=str_replace('<p/>','',$v);
- $v=preg_replace('/<ahref=".+"target="_blank"><strong>(.+)</strong></a>/usi','',$v);
- $v=preg_replace('%(<spans*[^>]*>(.*)</span>)%usi','',$v);
- $v=preg_replace('%(s+class="mso[^"]+")%si','',$v);
- $v=preg_replace('%(style="[^"]*mso[^>]*)%si','',$v);
- $v=preg_replace('/<b></b>/','',$v);
- return$v;
- }
- /**
- *striptitletag($title)对文章标题进行过滤
- *@paramstring$v
- *@returnstring
- */
- functionstripauthortag($v){
- $v=preg_replace('/<ahref=".+"target="_blank">(.+)</a>/usi','',$v);
- return$v;
- }
- /**
- *mysqlstring($str)过滤数据
- *@paramstring$str
- *@returnstring
- */
- functionmysqlstring($str){
- returnaddslashes(trim($str));
- }
- /**
- *init($min,$max)入口程序方法,从$min页开始取,到$max页结束
- *@paramint$min从1开始
- *@paramint$max
- *@returnstring返回url地址
- */
- functioninit($min=1,$max){
- for($i=$min;$i<=$max;$i++){
- data("http://www.hqew.com/info-c10-{$i}.html");
- }
- }
- init(1,500);//程序入口,从第一页开始抓,抓取500页
- ?>
通过上面的程序,就可以实现抓取华强电子网的资讯信息。
入口方法 init($min, $max) 如果想抓取 1-500 页面内容,那么 init(1, 500) 即可!这样,用不了多长时间,华强电子网的资讯就会全部抓取到数据库里面了。^_^
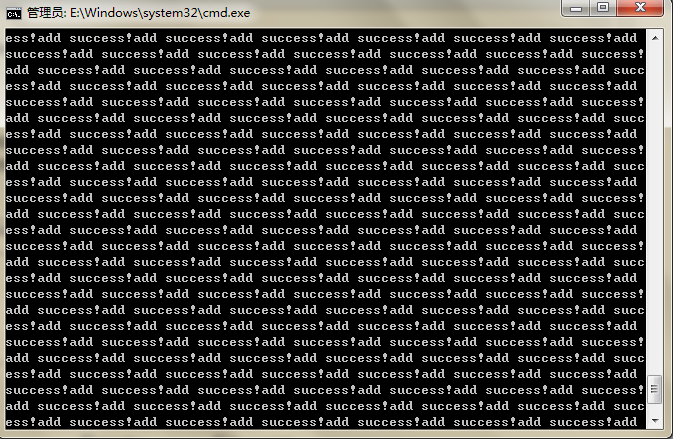
执行界面:
数据库:

相关文章


- 64M VPS建站:是否适合初学者操作和管理? 2025-06-10
- ASP.NET自助建站系统中的用户注册和登录功能定制方法 2025-06-10
- ASP.NET自助建站系统的域名绑定与解析教程 2025-06-10
- 个人服务器网站搭建:如何选择合适的服务器提供商? 2025-06-10
- ASP.NET自助建站系统中如何实现多语言支持? 2025-06-10