在网络爬虫中,经常会遇到如下报错。即连接超时。针对此问题,一般解决思路为:将连接时间、请求时间设置长一下。如果出现连接超时的情况,则在重新请求【设置重新请求次数】。
?

|
1
|
Exception in thread "main" java.net.ConnectException: Connection timed out: connect
|
下面的代码便是使用httpclient解决连接超时的样例程序。直接上程序。
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
package daili;
import java.io.IOException;
import java.net.URI;
import org.apache.http.HttpRequest;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.params.CookiePolicy;
import org.apache.http.client.protocol.ClientContext;
import org.apache.http.impl.client.BasicCookieStore;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.impl.client.DefaultHttpRequestRetryHandler;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.cookie.BasicClientCookie2;
import org.apache.http.params.HttpConnectionParams;
import org.apache.http.params.HttpParams;
import org.apache.http.protocol.BasicHttpContext;
import org.apache.http.protocol.ExecutionContext;
import org.apache.http.protocol.HttpContext;
import org.apache.http.util.EntityUtils;
/*
* author:合肥工业大学 管院学院 钱洋
*1563178220@qq.com
*/
public class Test1 {
public static void main(String[] args) throws ClientProtocolException, IOException, InterruptedException {
getRawHTML("http://club.autohome.com.cn/bbs/forum-c-2098-1.html#pvareaid=103447");
}
public static String getRawHTML ( String url ) throws ClientProtocolException, IOException, InterruptedException{
//初始化
DefaultHttpClient httpclient = new DefaultHttpClient();
httpclient.getParams().setParameter("http.protocol.cookie-policy",
CookiePolicy.BROWSER_COMPATIBILITY);
//设置参数
HttpParams params = httpclient.getParams();
//连接时间
HttpConnectionParams.setConnectionTimeout(params, 6000);
HttpConnectionParams.setSoTimeout(params, 6000*20);
//超时重新请求次数
DefaultHttpRequestRetryHandler dhr = new DefaultHttpRequestRetryHandler(5,true);
HttpContext localContext = new BasicHttpContext();
HttpRequest request2 = (HttpRequest) localContext.getAttribute(
ExecutionContext.HTTP_REQUEST);
httpclient.setHttpRequestRetryHandler(dhr);
BasicCookieStore cookieStore = new BasicCookieStore();
BasicClientCookie2 cookie = new BasicClientCookie2("Content-Type","text/html;charset=UTF-8");
BasicClientCookie2 cookie1 = new BasicClientCookie2("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36");
cookieStore.addCookie(cookie);
cookieStore.addCookie(cookie1);
localContext.setAttribute(ClientContext.COOKIE_STORE, cookieStore);
HttpGet request = new HttpGet();
request.setURI(URI.create(url));
HttpResponse response = null;
String rawHTML = "";
response = httpclient.execute(request,localContext);
int StatusCode = response.getStatusLine().getStatusCode();
//获取响应状态码
System.out.println(StatusCode);
if(StatusCode == 200){
//状态码200表示响应成功
//获取实体内容
rawHTML = EntityUtils.toString (response.getEntity());
System.out.println(rawHTML);
//输出实体内容
EntityUtils.consume(response.getEntity());
//消耗实体
} else {
//关闭HttpEntity的流实体
EntityUtils.consume(response.getEntity());
//消耗实体
Thread.sleep(20*60*1000);
//如果报错先休息30分钟
}
httpclient.close();
System.out.println(rawHTML);
return rawHTML;
}
}
|
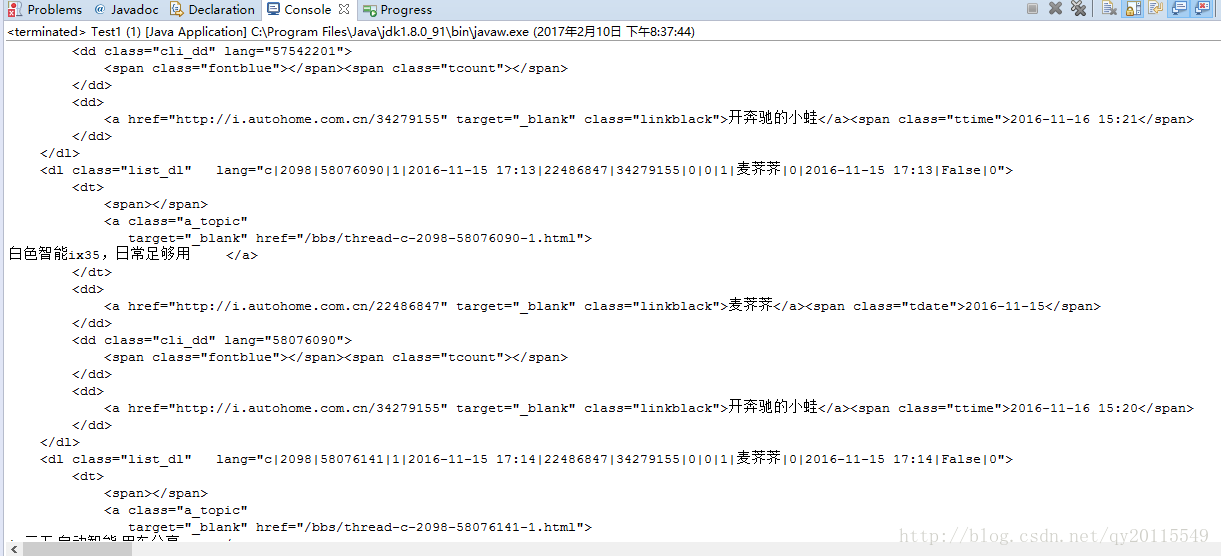
结果:
总结
以上就是本文关于java网络爬虫连接超时解决实例代码的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
原文链接:http://blog.csdn.net/qy20115549/article/details/54973952

相关文章


猜你喜欢
- 64M VPS建站:是否适合初学者操作和管理? 2025-06-10
- ASP.NET自助建站系统中的用户注册和登录功能定制方法 2025-06-10
- ASP.NET自助建站系统的域名绑定与解析教程 2025-06-10
- 个人服务器网站搭建:如何选择合适的服务器提供商? 2025-06-10
- ASP.NET自助建站系统中如何实现多语言支持? 2025-06-10