

这是一个系列 没办法在一两天写完 所以一篇一篇的发布
大致大纲:
2.curl数据采集系列之多页面并行采集函数get_htmls
3.curl数据采集系列之正则处理函数get _matches
4.curl数据采集系列之代码分离
5.curl数据采集系列之并行逻辑控制函数web_spider
单页面采集在数据采集过程中是最常用的一个功能 有时在服务器访问限制的情况下 只能使用这种采集方式 慢 但是可以简单的控制 所以写好一个常用的curl函数调用是很重要的
百度和网易比较熟悉 所以拿这两个网站首页采集来做例子讲解
最简单的写法:
复制代码 代码如下:
$url = 'http://www.baidu.com';
$ch = curl_init($url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
curl_setopt($ch,CURLOPT_TIMEOUT,5);
$html = curl_exec($ch);
if($html !== false){
echo $html;
}
$url = 'http://www.baidu.com';
$ch = curl_init($url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
curl_setopt($ch,CURLOPT_TIMEOUT,5);
$html = curl_exec($ch);
if($html !== false){
echo $html;
}
由于使用频繁 可以利用curl_setopt_array写成函数的形式:
复制代码 代码如下:
function get_html($url,$options = array()){
$options[CURLOPT_RETURNTRANSFER] = true;
$options[CURLOPT_TIMEOUT] = 5;
$ch = curl_init($url);
curl_setopt_array($ch,$options);
$html = curl_exec($ch);
curl_close($ch);
if($html === false){
return false;
}
return $html;
}
function get_html($url,$options = array()){
$options[CURLOPT_RETURNTRANSFER] = true;
$options[CURLOPT_TIMEOUT] = 5;
$ch = curl_init($url);
curl_setopt_array($ch,$options);
$html = curl_exec($ch);
curl_close($ch);
if($html === false){
return false;
}
return $html;
}
复制代码 代码如下:
$url = 'http://www.baidu.com';
echo get_html($url);
$url = 'http://www.baidu.com';
echo get_html($url);
有时候需要传递一些特定的参数才能得到正确的页面 如现在要得到网易的页面:
复制代码 代码如下:
$url = 'http://www.163.com';
echo get_html($url);
$url = 'http://www.163.com';
echo get_html($url);
会看到一片空白 什么也没有 那么再利用curl_getinfo写一个函数 看看发生了什么:
复制代码 代码如下:
function get_info($url,$options = array()){
$options[CURLOPT_RETURNTRANSFER] = true;
$options[CURLOPT_TIMEOUT] = 5;
$ch = curl_init($url);
curl_setopt_array($ch,$options);
$html = curl_exec($ch);
$info = curl_getinfo($ch);
curl_close($ch);
return $info;
}
$url = 'http://www.163.com';
var_dump(get_info($url));
function get_info($url,$options = array()){
$options[CURLOPT_RETURNTRANSFER] = true;
$options[CURLOPT_TIMEOUT] = 5;
$ch = curl_init($url);
curl_setopt_array($ch,$options);
$html = curl_exec($ch);
$info = curl_getinfo($ch);
curl_close($ch);
return $info;
}
$url = 'http://www.163.com';
var_dump(get_info($url));

可以看到http_code302重定向了这时候就需要传递一些参数了:
复制代码 代码如下:
$url = 'http://www.163.com';
$options[CURLOPT_FOLLOWLOCATION] = true;
echo get_html($url,$options);

$url = 'http://www.163.com';
$options[CURLOPT_FOLLOWLOCATION] = true;
echo get_html($url,$options);
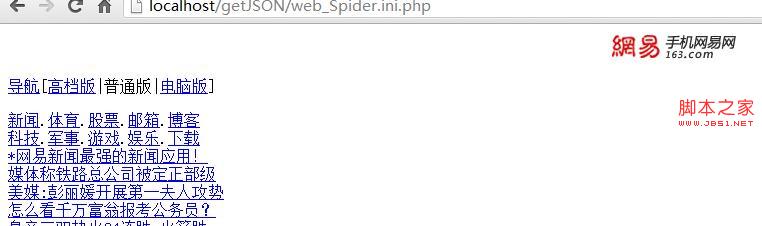
会发现怎么是这样的一个页面和我们电脑访问的不同???
看来参数还是不够不够服务器判断我们的客户端是什么设备上的就返回了个普通版
看来还要传送USERAGENT
复制代码 代码如下:
$url = 'http://www.163.com';
$options[CURLOPT_FOLLOWLOCATION] = true;
$options[CURLOPT_USERAGENT] = 'Mozilla/5.0 (Windows NT 6.1; rv:19.0) Gecko/20100101 Firefox/19.0';
echo get_html($url,$options);
$url = 'http://www.163.com';
$options[CURLOPT_FOLLOWLOCATION] = true;
$options[CURLOPT_USERAGENT] = 'Mozilla/5.0 (Windows NT 6.1; rv:19.0) Gecko/20100101 Firefox/19.0';
echo get_html($url,$options);

OK现在页面已经出来了这样基本这个get_html函数基本能实现这样扩展的功能
当然也有另外的办法可以实现,当你明确的知道网易的网页的时候就可以简单采集了:
复制代码 代码如下:

相关文章



猜你喜欢
- ASP.NET本地开发时常见的配置错误及解决方法? 2025-06-10
- ASP.NET自助建站系统的数据库备份与恢复操作指南 2025-06-10
- 个人网站服务器域名解析设置指南:从购买到绑定全流程 2025-06-10
- 个人网站搭建:如何挑选具有弹性扩展能力的服务器? 2025-06-10
- 个人服务器网站搭建:如何选择适合自己的建站程序或框架? 2025-06-10




