Kubernetes 的节点可以按照节点的资源容量进行调度,默认情况下 Pod 能够使用节点全部可用容量。这样就会造成一个问题,因为节点自己通常运行了不少驱动 OS 和 Kubernetes 的系统守护进程。除非为这些系统守护进程留出资源,否则它们将与 Pod 争夺资源并导致节点资源短缺问题。
当我们在线上使用 Kubernetes 集群的时候,如果没有对节点配置正确的资源预留,我们可以考虑一个场景,由于某个应用无限制的使用节点的 CPU 资源,导致节点上 CPU 使用持续100%运行,而且压榨到了 kubelet 组件的 CPU 使用,这样就会导致 kubelet 和 apiserver 的心跳出问题,节点就会出现 Not Ready 状况了。默认情况下节点 Not Ready 过后,5分钟后会驱逐应用到其他节点,当这个应用跑到其他节点上的时候同样100%的使用 CPU,是不是也会把这个节点搞挂掉,同样的情况继续下去,也就导致了整个集群的雪崩,集群内的节点一个一个的 Not Ready 了,后果是非常严重的,或多或少的人遇到过 Kubernetes 集群雪崩的情况,这个问题也是面试的时候镜像询问的问题。
要解决这个问题就需要为 Kubernetes 集群配置资源预留,kubelet 暴露了一个名为 Node Allocatable 的特性,有助于为系统守护进程预留计算资源,Kubernetes 也是推荐集群管理员按照每个节点上的工作负载来配置 Node Allocatable。
本文的操作环境为 Kubernetes v1.22.1 版本,使用 Containerd 的容器运行时,Containerd 和 Kubelet 采用的 cgroup 驱动为 systemd。
Node Allocatable
Kubernetes 节点上的 Allocatable 被定义为 Pod 可用计算资源量,调度器不会超额申请 Allocatable,目前支持 CPU, memory 和 ephemeral-storage 这几个参数。
我们可以通过 kubectl describe node 命令查看节点可分配资源的数据:
- ➜~kubectldescribenodenode2
- ……
- Capacity:
- cpu:4
- ephemeral-storage:36678148Ki
- hugepages-1Gi:0
- hugepages-2Mi:0
- memory:7990056Ki
- pods:110
- Allocatable:
- cpu:4
- ephemeral-storage:33802581141
- hugepages-1Gi:0
- hugepages-2Mi:0
- memory:7887656Ki
- pods:110
- ……
可以看到其中有 Capacity 与 Allocatable 两项内容,其中的 Allocatable 就是节点可被分配的资源,我们这里没有配置资源预留,所以默认情况下 Capacity 与 Allocatable 的值基本上是一致的。下图显示了可分配资源和资源预留之间的关系:
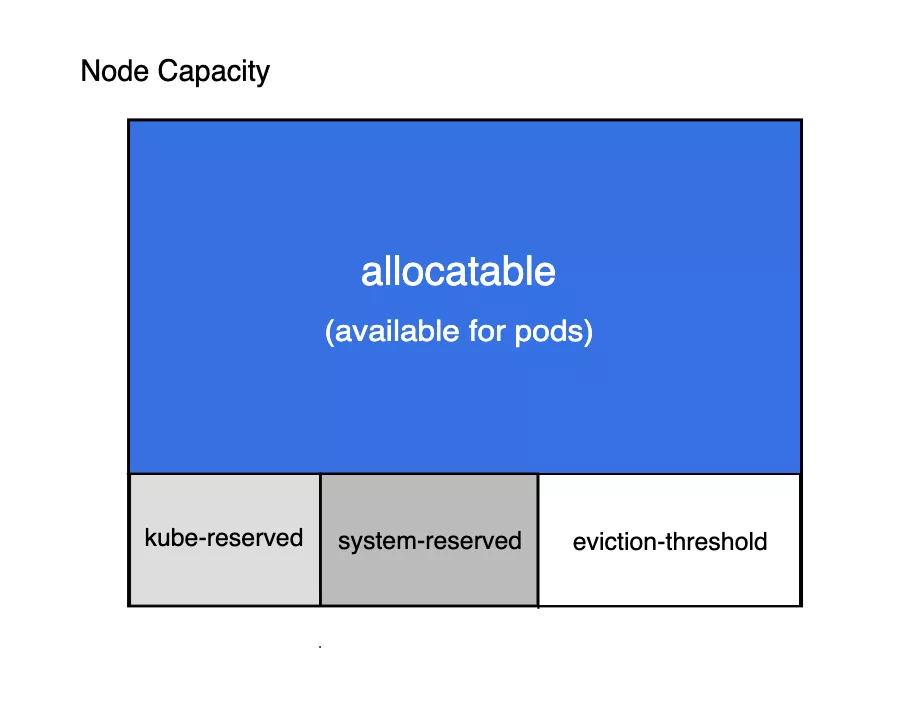
Node Allocatable
- Kubelet Node Allocatable 用来为 Kube 组件和 System 进程预留资源,从而保证当节点出现满负荷时也能保证 Kube 和 System 进程有足够的资源。
- 目前支持 cpu, memory, ephemeral-storage 三种资源预留。
- Node Capacity 是节点的所有硬件资源,kube-reserved 是给 kube 组件预留的资源,system-reserved 是给系统进程预留的资源,eviction-threshold 是 kubelet 驱逐的阈值设定,allocatable 才是真正调度器调度 Pod 时的参考值(保证节点上所有 Pods 的 request 资源不超过 Allocatable)。
节点可分配资源的计算方式为:
- NodeAllocatableResource=NodeCapacity-Kube-reserved-system-reserved-eviction-threshold
调度到某个节点上的 Pod 的 requests 总和不能超过该节点的 allocatable。
配置资源预留
比如我们现在需要为系统预留一定的资源,我们可以使用如下的几个 kubelet 参数来进行配置:
- –enforce-node-allocatable=pods
- –kube-reserved=memory=…
- –system-reserved=memory=…
- –eviction-hard=…
这里我们暂时不设置对应的 cgroup,比如我们这里先只对 node2 节点添加资源预留,我们可以直接修改 /var/lib/kubelet/config.yaml 文件来动态配置 kubelet,添加如下所示的资源预留配置:
- apiVersion:kubelet.config.k8s.io/v1beta1
- ……
- enforceNodeAllocatable:
- -pods
- kubeReserved:#配置kube资源预留
- cpu:500m
- memory:1Gi
- ephemeral-storage:1Gi
- systemReserved:#配置系统资源预留
- memory:1Gi
- evictionHard:#配置硬驱逐阈值
- memory.available:"300Mi"
- nodefs.available:"10%"
修改完成后,重启 kubelet,启动完成后重新对比 Capacity 及 Allocatable 的值:
- ➜~kubectldescribenodenode2
- ……
- Capacity:
- cpu:4
- ephemeral-storage:36678148Ki
- hugepages-1Gi:0
- hugepages-2Mi:0
- memory:7990056Ki
- pods:110
- Allocatable:
- cpu:3500m
- ephemeral-storage:32728839317
- hugepages-1Gi:0
- hugepages-2Mi:0
- memory:5585704Ki
- pods:110
仔细对比可以发现其中的 Allocatable的值恰好是 Capacity 减去上面我们配置的预留资源的值:
- allocatale=capacity-kube_reserved-system_reserved-eviction_hard
- 5585704Ki=7990056Ki-1*1024*1024Ki-1*1024*1024Ki-300*1024Ki
再通过查看 kubepods.slice(systemd 驱动是以 .slice 结尾)cgroup 中对节点上所有 Pod 内存的限制,该值决定了 Node 上所有的 Pod 能使用的资源上限:
- ➜~cat/sys/fs/cgroup/memory/kubepods.slice/memory.limit_in_bytes
- 6034333696
得到的 Pod 资源使用上限为:
- 6034333696Bytes=5892904Ki=Allocatable(5585704Ki)+eviction_hard(300*1024Ki)
也可以通过计算验证我们的配置是正确的:
- kubepods.slice/memory.limit_in_bytes=capacity-kube_reserved-system_reserved
Eviction 与 OOM
1、eviction 是指 kubelet 对该节点上的 Pod 进行驱逐,OOM 是指 cgroup 对进程进行 kill
2、kubelet 对 Pod 进行驱逐时,是根据 –eviction-hard 参数,比如该参数如果设置了 memory.available<20%,那么当主机的内存使用率达到80%时,kubelet 便会对Pod进行驱逐。但是,–eviction-hard=memory.available<20% 不会对 /sys/fs/cgroup/memory/kubepods.slice/memory.limit_in_bytes 的值产生影响,因为 kubepods.slice/memory.limit_in_bytes = capacity – kube-reserved – system-reserved,换句话说,Pod 的内存使用量总和是可以超过80%的,且不会被 OOM-kill,只会被 eviction。
3、kubernetes 对 Pod 的驱逐机制如下(其实就是 QoS 章节的定义):
- 首先驱逐没有设置资源限制的 Pod
- 然后驱逐资源上限和资源下限不一样的 Pod
- 最后驱逐资源上限等资源下限的Pod
可分配约束
前面我们在配置资源预留的时候其中有一个 enforceNodeAllocatable 配置项(–enforce-node-allocatable),该配置项的帮助信息为:
- –enforce-node-allocatablestringsAcommaseparatedlistoflevelsofnodeallocatableenforcementtobeenforcedbykubelet.Acceptableoptionsare'none','pods','system-reserved',and'kube-reserved'.Ifthelattertwooptionsarespecified,'–system-reserved-cgroup'and'–kube-reserved-cgroup'mustalsobeset,respectively.If'none'isspecified,noadditionaloptionsshouldbeset.Seehttps://kubernetes.io/docs/tasks/administer-cluster/reserve-compute-resources/formoredetails.(default[pods])(DEPRECATED:ThisparametershouldbesetviatheconfigfilespecifiedbytheKubelet's–configflag.Seehttps://kubernetes.io/docs/tasks/administer-cluster/kubelet-config-file/formoreinformation.)
kubelet 默认对 Pod 执行 Allocatable 可分配约束,如果所有 Pod 的总用量超过了 Allocatable,那么驱逐 Pod 的措施将被执行,我们可以可通过设置 kubelet –enforce-node-allocatable 标志值为 pods 控制这个措施。
此外我们还可以通过该标志来同时指定 kube-reserved 和 system-reserved 值,可以让 kubelet 强制实施 kube-reserved 和 system-reserved 约束,不过需要注意,如果配置了 kube-reserved 或者 system-reserved 约束,那么需要对应设置 –kube-reserved-cgroup 或者 –system-reserved-cgroup 参数。
如果设置了对应的 –system-reserved-cgroup 和 –kube-reserved-cgroup 参数,Pod 能实际使用的资源上限是不会改变,但系统进程与 kube 进程也会受到资源上限的限制,如果系统进程超过了预留资源,那么系统进程会被 cgroup 杀掉。但是如果不设这两个参数,那么系统进程就可以使用超过预留的资源上限。
所以如果要为系统预留和 kube 预留配置 cgroup,则需要非常小心,如果执行了 kube-reserved 约束,那么 kubelet 就不能出现突发负载用光所有可用资源,不然就会被杀掉。system-reserved 可以用于为诸如 sshd、udev 等系统守护进程争取资源预留,但是如果执行 system-reserved 约束,那么可能因为某些原因导致节点上的关键系统服务 CPU 资源短缺或因为内存不足而被终止,所以如果不是自己非常清楚如何配置,最好别配置 cgroup 约束,如果需要自行配置,可以参考第一期的资源预留文档进行相关操作。
因此,我们强烈建议用户使用 enforce-node-allocatable 默认配置的 pods 即可,并为系统和 kube 进程预留出适当的资源,以保持整体节点的可靠性,不需要进行 cgroup 约束,除非操作人员对系统非常了解。
原文链接:https://mp.weixin.qq.com/s/GueahMq2t4NBPw1lvNc_IA