

jdk1.7.0_79
对于线程池大部分人可能会用,也知道为什么用。无非就是任务需要异步执行,再者就是线程需要统一管理起来。对于从线程池中获取线程,大部分人可能只知道,我现在需要一个线程来执行一个任务,那我就把任务丢到线程池里,线程池里有空闲的线程就执行,没有空闲的线程就等待。实际上对于线程池的执行原理远远不止这么简单。
在Java并发包中提供了线程池类——ThreadPoolExecutor,实际上更多的我们可能用到的是Executors工厂类为我们提供的线程池:newFixedThreadPool、newSingleThreadPool、newCachedThreadPool,这三个线程池并不是ThreadPoolExecutor的子类,关于这几者之间的关系,我们先来查看ThreadPoolExecutor,查看源码发现其一共有4个构造方法。
|
1
|
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)
|
首先就从这几个参数开始来了解线程池ThreadPoolExecutor的执行原理。
corePoolSize:核心线程池的线程数量
maximumPoolSize:最大的线程池线程数量
keepAliveTime:线程活动保持时间,线程池的工作线程空闲后,保持存活的时间。
unit:线程活动保持时间的单位。
workQueue:指定任务队列所使用的阻塞队列
corePoolSize和maximumPoolSize都在指定线程池中的线程数量,好像平时用到线程池的时候最多就只需要传递一个线程池大小的参数就能创建一个线程池啊,Java为我们提供了一些常用的线程池类就是上面提到的newFixedThreadPool、newSingleThreadExecutor、newCachedThreadPool,当然如果我们想要自己发挥创建自定义的线程池就得自己来“配置”有关线程池的一些参数。
当把一个任务交给线程池来处理的时候,线程池的执行原理如下图所示参考自《Java并发编程的艺术》
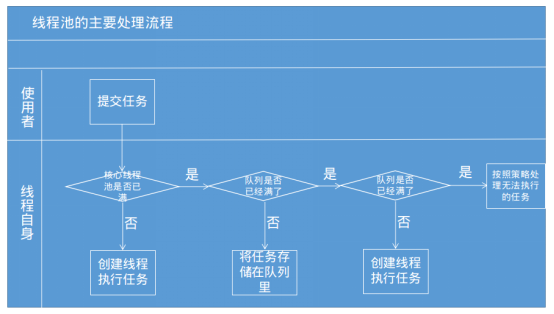
①首先会判断核心线程池里是否有线程可执行,有空闲线程则创建一个线程来执行任务。
②当核心线程池里已经没有线程可执行的时候,此时将任务丢到任务队列中去。
③如果任务队列(有界)也已经满了的话,但运行的线程数小于最大线程池的数量的时候,此时将会新建一个线程用于执行任务,但如果运行的线程数已经达到最大线程池的数量的时候,此时将无法创建线程执行任务。
所以实际上对于线程池不仅是单纯地将任务丢到线程池,线程池中有线程就执行任务,没线程就等待。
为巩固一下线程池的原理,现在再来了解上面提到的常用的3个线程池:
Executors.newFixedThreadPool:创建一个固定数量线程的线程池。
|
1
2
3
4
|
// Executors#newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}
|
可以看到newFixedThreadPool中调用的是ThreadPoolExecutor类,传递的参数corePoolSize= maximumPoolSize=nThread。回顾线程池的执行原理,当一个任务提交到线程池中,首先判断核心线程池里有没有空闲线程,有则创建线程,没有则将任务放到任务队列(这里是有界阻塞队列LinkedBlockingQueue)中,如果任务队列已经满了的话,对于newFixedThreadPool来说,它的最大线程池数量=核心线程池数量,此时任务队列也满了,将不能扩展创建新的线程来执行任务。
Executors.newSingleThreadExecutor:创建只包含一个线程的线程池。
|
1
2
3
4
|
//Executors# newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegateExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}
|
只有一个线程的线程池好像有点奇怪,并且并没有直接将返回ThreadPoolExecutor,甚至也没有直接将线程池数量1传递给newFixedThreadPool返回。那就说明这个只含有一个线程的线程池,或许并没有只包含一个线程那么简单。在其源码注释中这么写到:创建只有一个工作线程的线程池用于操作一个无界队列(如果由于前驱节点的执行被终止结束了,一个新的线程将会继续执行后继节点线程)任务得以继续执行,不同于newFixedThreadPool(1)不会有额外的线程来重新继续执行后继节点。也就是说newSingleThreadExecutor自始至终都只有一个线程在执行,这和newFixedThreadPool一样,但如果线程终止结束过后newSingleThreadExecutor则会重新创建一个新的线程来继续执行任务队列中的线程,而newFixedThreaPool则不会。
Executors.newCachedThreadPool:根据需要创建新线程的线程池。
|
1
2
3
4
|
//Executors#newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPooExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}
|
可以看到newCachedThread返回的是ThreadPoolExecutor,其参数核心线程池corePoolSize = 0, maximumPoolSize = Integer.MAX_VALUE,这也就是说当任务被提交到newCachedThread线程池时,将会直接把任务放到SynchronousQueue任务队列中,maximumPool从任务队列中获取任务。注意SynchronousQueue是一个没有容量的队列,也就是说每个入队操作必须等待另一个线程的对应出队操作,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,newCachedThreadPool会不断创建线程,线程多并不是一件好事,严重会耗尽CPU和内存资源。
题外话:newFixedThreadPool、newSingleThreadExecutor、newCachedThreadPool,这三者都直接或间接调用了ThreadPoolExecutor,为什么它们三者没有直接是其子类,而是通过Executors来实例化呢?这是所采用的静态工厂方法,在java.util.Connections接口中同样也是采用的静态工厂方法来创建相关的类。这样有很多好处,静态工厂方法是用来产生对象的,产生什么对象没关系,只要返回原返回类型或原返回类型的子类型都可以,降低API数目和使用难度,在《Effective Java》中的第1条就是静态工厂方法。
回到ThreadPoolExecutor,首先来看它的继承关系:
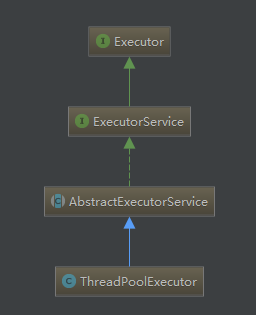
ThreadPoolExecutor它的顶级父类是Executor接口,只包含了一个方法——execute,这个方法也就是线程池的“执行”。
|
1
2
3
4
|
//Executor#execute
public interface Executor {
void execute(Runnable command);
}
|
Executor#execute的实现则是在ThreadPoolExecutor中实现的:
|
1
2
3
4
5
6
7
|
//ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
…
}
|
一来就碰到个不知所云的ctl变量它的定义:
private final AtomicInteger ctl = new AtlmicInteger(ctlOf(RUNNING, 0));
这个变量使用来干嘛的呢?它的作用有点类似我们在《ReadWriteLock接口及其实现ReentrantReadWriteLock》中提到的读写锁有读、写两个同步状态,而AQS则只提供了state一个int型变量,此时将state高16位表示为读状态,低16位表示为写状态。这里的clt同样也是,它表示了两个概念:
workerCount:当前有效的线程数
runState:当前线程池的五种状态,Running、Shutdown、Stop、Tidying、Terminate。
int型变量一共有32位,线程池的五种状态runState至少需要3位来表示,故workCount只能有29位,所以代码中规定线程池的有效线程数最多为229-1。
|
1
2
3
4
5
6
7
8
9
|
//ThreadPoolExecutor
private static final int COUNT_BITS = Integer.SIZE – 3; //32-3=29,线程数量所占位数
private static final int CAPACITY = (1 << COUNT_BITS) – 1; //低29位表示最大线程数,229-1
//五种线程池状态
private static final int RUNNING = -1 << COUNT_BITS; /int型变量高3位(含符号位)101表RUNING
private static final int SHUTDOWN = 0 << COUNT_BITS; //高3位000
private static final int STOP = 1 << COUNT_BITS; //高3位001
private static final int TIDYING = 2 << COUNT_BITS; //高3位010
private static final int TERMINATED = 3 << COUNT_BITS; //高3位011
|
再次回到ThreadPoolExecutor#execute方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
//ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get(); //由它可以获取到当前有效的线程数和线程池的状态
/*1.获取当前正在运行线程数是否小于核心线程池,是则新创建一个线程执行任务,否则将任务放到任务队列中*/
if (workerCountOf(c) < corePoolSize){
if (addWorker(command, tre)) //在addWorker中创建工作线程执行任务
return ;
c = ctl.get();
}
/*2.当前核心线程池中全部线程都在运行workerCountOf(c) >= corePoolSize,所以此时将线程放到任务队列中*/
if (isRunning(c) && workQueue.offer(command)) { //线程池是否处于运行状态,且是否任务插入任务队列成功
int recheck = ctl.get();
if (!isRunning(recheck) && remove(command)) //线程池是否处于运行状态,如果不是则使刚刚的任务出队
reject(command); //抛出RejectedExceptionException异常
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
/*3.插入队列不成功,且当前线程数数量小于最大线程池数量,此时则创建新线程执行任务,创建失败抛出异常*/
else if (!addWorker(command, false)){
reject(command); //抛出RejectedExceptionException异常
}
}
|
上面代码注释第7行的即判断当前核心线程池里是否有空闲线程,有则通过addWorker方法创建工作线程执行任务。addWorker方法较长,筛选出重要的代码来解析。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
//ThreadPoolExecutor#addWorker
private boolean addWorker(Runnable firstTask, boolean core) {
/*首先会再次检查线程池是否处于运行状态,核心线程池中是否还有空闲线程,都满足条件过后则会调用compareAndIncrementWorkerCount先将正在运行的线程数+1,数量自增成功则跳出循环,自增失败则继续从头继续循环*/
...
if (compareAndIncrementWorkerCount(c))
break retry;
...
/*正在运行的线程数自增成功后则将线程封装成工作线程Worker*/
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
final ReentrantLock mainLock = this.mainLock; //全局锁
w = new Woker(firstTask); //将线程封装为Worker工作线程
final Thread t = w.thread;
if (t != null) {
mainLock.lock(); //获取全局锁
/*当持有了全局锁的时候,还需要再次检查线程池的运行状态等*/
try {
int c = clt.get();
int rs = runStateOf(c); //线程池运行状态
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)){ //线程池处于运行状态,或者线程池关闭且任务线程为空
if (t.isAlive()) //线程处于活跃状态,即线程已经开始执行或者还未死亡,正确的应线程在这里应该是还未开始执行的
throw new IllegalThreadStateException();
workers.add(w); //private final HashSet<Worker> wokers = new HashSet<Worker>();包含线程池中所有的工作线程,只有在获取了全局的时候才能访问它。将新构造的工作线程加入到工作线程集合中
int s = worker.size(); //工作线程数量
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true; //新构造的工作线程加入成功
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); //在被构造为Worker工作线程,且被加入到工作线程集合中后,执行线程任务,注意这里的start实际上执行Worker中run方法,所以接下来分析Worker的run方法
workerStarted = true;
}
}
} finally {
if (!workerStarted) //未能成功创建执行工作线程
addWorkerFailed(w); //在启动工作线程失败后,将工作线程从集合中移除
}
return workerStarted;
}
|
在上面第35代码中,工作线程被成功添加到工作线程集合中后,则开始start执行,这里start执行的是Worker工作线程中的run方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
//ThreadPoolExecutor$Worker,它继承了AQS,同时实现了Runnable,所以它具备了这两者的所有特性
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread;
Runnable firstTask;
public Worker(Runnable firstTask) {
setState(-1); //设置AQS的同步状态为-1,禁止中断,直到调用runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); //通过线程工厂来创建一个线程,将自身作为Runnable传递传递
}
public void run() {
runWorker(this); //运行工作线程
}
}
|
ThreadPoolExecutor#runWorker,在此方法中,Worker在执行完任务后,还会循环获取任务队列里的任务执行(其中的getTask方法),也就是说Worker不仅仅是在执行完给它的任务就释放或者结束,它不会闲着,而是继续从任务队列中获取任务,直到任务队列中没有任务可执行时,它才退出循环完成任务。理解了以上的源码过后,往后线程池执行原理的第二步、第三步的理解实则水到渠成。
以上这篇ThreadPoolExecutor线程池原理及其execute方法(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持快网idc。

相关文章



- ASP.NET本地开发时常见的配置错误及解决方法? 2025-06-10
- ASP.NET自助建站系统的数据库备份与恢复操作指南 2025-06-10
- 个人网站服务器域名解析设置指南:从购买到绑定全流程 2025-06-10
- 个人网站搭建:如何挑选具有弹性扩展能力的服务器? 2025-06-10
- 个人服务器网站搭建:如何选择适合自己的建站程序或框架? 2025-06-10





