简介
集合和数组的区别:
数组存储基础数据类型,且每一个数组都只能存储一种数据类型的数据,空间不可变。
集合存储对象,一个集合中可以存储多种类型的对象。空间可变。
严格地说,集合是存储对象的引用,每个对象都称为集合的元素。根据存储时数据结构的不同,分为几类集合。但对象不管存储到什么类型的集合中,既然集合能存储任何类型的对象,这些对象在存储时都必须向上转型为object类型,也就是说,集合中的元素都是object类型的对象。
既然是集合,无论分为几类,它都有集合的共性,也就是说虽然存储时数据结构不一样,但该有的集合方法还是得有。在java中,collection接口是集合框架的根接口,所有集合的类型都实现了此接口或从其子接口中继承。
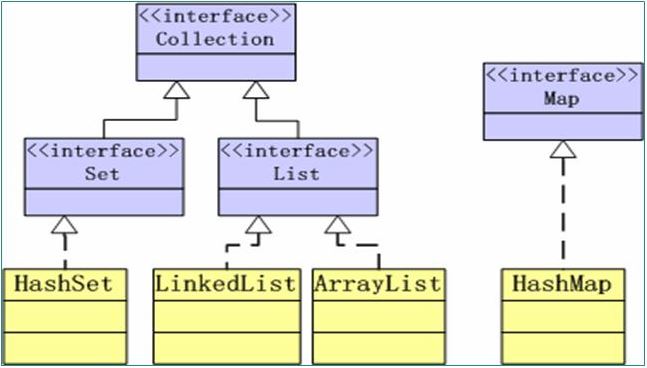
collection接口
根据数据结构的不同,一些collection允许有重复的元素,而另一些则不允许。一些collection是有序的,而另一些则是无序的。
java sdk不提供直接继承自collection的类,java sdk提供的类都是继承自collection的"子接口"如list和set。也就是说,无法直接new一个collection对象,而是只能new一个实现collection类的子接口的对象,如new arraylist();。
所有的collection类都必须至少提供两个构造方法:无参数构造方法构造一个空集合;带collection参数的构造方法构造一个包含该collection内容的集合。例如,arraylist就有3个构造方法,其中之二就满足这两个构造方法的要求。
collection是java.util包中的类,因此要实现集合的概念,需要先导入该包。
arraylist继承自list接口,list接口又继承自collection接口。arraylist类存储的集合中,元素有序、可重复。
import java.util.*;
collection coll = new arraylist();
因为collection接口不允许直接实现,因此需要通过实现它的子类来实现集合的概念,此处创建的是arraylist对象,使用了父类引用,好处是扩展性较好。
collection有一些集合的通用性操作方法,分为两类:一类是普通方法;一类是带有all的方法,这类方法操作的是集合。
add():向集合的尾部插入元素,返回值类型为boolean,插入成功返回true。注意集合只能存储对象(实际上是对象的引用)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
import java.util.*;
//
public class testcoll {
public static void main(string[] args) {
collection coll = new arraylist();
coll.add("abcd");
//插入字符串对象
coll.add(123);
//插入int对象
coll.add(123);
coll.add(new student("gaoxiaof",23));
//插入student对象
coll.add(new student("gaoxiaof",23));
//插入另一个student对象
system.out.println(coll);
//直接输出集合中的元素,得到结果[abcd,123,123,gaoxiaof 23,gaoxiaof 23]
}
}
//
class student {
private string name;
private int age;
student(string name,int n) {
this.name = name;
this.age = n;
}
public string getname() {
return this.name;
}
public int getage() {
return this.age;
}
public string tostring() {
return this.name + " " + this.age;
}
}
|
上面插入的"abcd"和"123"都是经过自动装箱转换为对象后存储在集合中的。其中两个add(123)是重复的对象元素,因为判断集合中的元素是否重复的唯一方法是equals方法是否返回0。integer已经重写过equals()。而后面的两个student对象是不同对象,因为student类中没有重写equals()方法,所以它们是不重复的元素。
remove():删除集合中首次出现的元素。确定是否能删除某个元素,唯一的方法是通过equals()方法确定对象是否相等,相等时删除才返回true。
|
1
2
3
4
5
6
7
|
collection coll = new arraylist();
coll.add("abcd");
coll.add(new integer(128));
coll.add(new student("gaoxiaofang",23));
system.out.println(coll.remove(new integer(128))); //true
coll.remove(new student("gaoxiaofang",23)); //false,因为没有重写equals()
system.out.println(coll); //return: [abcd,gaoxiaofang 23]
|
clear():清空该集合中的所有元素。
contains(object obj):是否包含某对象元素。判断的依据仍然是equals()方法。
|
1
2
3
|
collection coll = new arraylist();
coll.add(new integer(128));
system.out.println(coll.contains(new integer(128))); //true
|
isempty():集合是否不包含任何元素。
size():返回该集合中元素的个数。
equals(object obj):比较两个集合是否完全相等。依据是集合中的所有元素都能通过各自的equals得到相等的比较。
addall(collection c):将整个集合c中的元素都添加到该集合中。
containsall(collection c):该集合是否包含了c集合中的所有元素,即集合c是否是该集合的子集。
removeall(collection c):删除该集合中那些也包含在c集合中的元素。即删除该集合和c集合的交集元素。
retainall(collection c):和removeall()相反,仅保留该集合中和集合c交集部分的元素。
iterator(collection c):返回此集合中的迭代器,注意返回值类型为iterator。迭代器用于遍历集合。见下文。
iterator通用迭代器
因为不同类型的集合存储数据时数据结构不同,想要写一个通用的遍历集合的方法是不现实的。但无论是哪种类型的集合,只有集合自身对集合中的元素是最了解的,因此在实现collection接口时,不同集合类都实现了自己独有的遍历方法,这称为集合的迭代器iterator。其实collection继承了java.lang.iterable接口,该接口只提供了一个方法:iterator(),只要是实现了这个接口的类就表示具有迭代的能力,也就具有foreach增强遍历的能力。
迭代器自身是一个接口,通过collection对象的iterator()方法就可以获取到对应集合类型的迭代器。例如:
collection coll = new arraylist();
iterator it = coll.iterator(); //获取对应类型的集合的迭代器
iterator接口提供了3个方法:
hasnext():判断是否有下一个元素。
next():获取下一个元素。注意它返回的是object(暂不考虑泛型)类型。
remove():移除迭代器最后返回的一个元素。此方法为collection迭代过程中修改元素的唯一安全的方法。
虽然有不同种类型的集合,但迭代器的迭代方法是通用的。例如,要遍历coll集合中的元素。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
import java.util.*;
public class testcoll {
public static void main(string[] args) {
collection coll = new arraylist();
coll.add("abcd");
coll.add(new integer(129));
coll.add(new student("gaoxiaofang",23));
iterator it = coll.iterator();
while (it.hasnext()) { //iterator遍历的方法
system.out.println(it.next()); //return:abcd,129,gaoxiaofang 23
}
}
}
class student {
private string name;
private int age;
student(string name,int n) {
this.name = name;
this.age = n;
}
public string getname() {
return this.name;
}
public int getage() {
return this.age;
}
public string tostring() {
return this.name + " " + this.age;
}
}
|
但是通常来说,上面的遍历方式虽然正确,但下面的遍历方式更佳。因为it对象只用于集合遍历,遍历结束后就应该消失,所以将其放入到for循环的内部,由于for循环的第三个表达式缺失,所以不断地循环第二个表达式即可。
for (iterator it = coll.iterator();it.hasnext();) {
system.out.println(it.next());
}
通过iterator遍历到的元素是集合中的一个对象,对象也是有属性的。如何引用这些属性?只需将遍历出的元素作为对象来使用即可,但由于next()返回的元素都是object对象,直接操作这个元素对象无法获取对应元素中的特有属性。因此必须先强制对象类型转换。
例如,获取coll中为student对象元素的name属性,并删除非student对象的元素。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
collection coll = new arraylist();
coll.add("abcd");
coll.add(new integer(129));
coll.add(new student("gaoxiaofang",23));
for (iterator it = coll.iterator();it.hasnext();) {
object obj = it.next();
if (obj instanceof student) {
student s = (student)obj;
system.out.println(s.getname()); //return: gaoxiaofang
} else {
it.remove();
}
}
system.out.println(coll); //return: [gaoxiaofang 23]
|
因为集合中有些非student对象元素,因此需要判断it.next()是否满足instanceof的要求,但不能直接写为下面的代码:
|
1
2
3
4
5
6
|
for (iterator it = coll.iterator();it.hasnext();) {
if (it.next() instanceof student) {
student s = (student)it.next();
system.out.println(s.getname());
}
}
|
因为每执行一次it.next(),元素的游标指针就向下滑动1,在这个写法中if判断表达式中使用了一次it.next(),在if的代码块中又调用了一次it.next()。所以应该将it.next()保存到对象变量中。而it.next()返回的类型是object类型,因此定义object obj = it.next()。
只有remove()方法是iterator迭代器迭代过程中修改集合元素且安全的方法。以迭代时add()为例,当开始迭代时,迭代器线程获取到集合中元素的个数,当迭代过程中执行add()时,它将采用另一个线程来执行(因为add()方法不是iterator接口提供的方法),结果是元素个数就增加了,且导致新增的元素无法确定是否应该作为迭代的一个元素。这是不安全的行为,因此会抛出concurrentmodificationexception异常。而remove()方法是迭代器自身的方法,它会使用迭代器线程来执行,因此它是安全的。
对于list类的集合来说,可以使用iterator的子接口listiterator来实现安全的迭代,该接口提供了不少增删改查list类集合的方法。
list接口
list接口实现了collection接口。
list接口的数据结构特性是:
1.有序列表,且带索引index。所谓有序指先后插入的顺序,即index决定顺序。而向set集合中插入数据会被打乱
2.大小可变。
3.数据可重复。
4.因为有序和大小可变,使得它除了有collection的特性,还有根据index精确增删改查某个元素的能力。
5.实现list接口的两个常用类为:
(1).arraylist:数组结构的有序列表;
1).长度可变,可变的原因是在减少或添加元素时部分下标整体减一或加一,如果已分配数组空间不够,则新创建一个更大的数组,并拷贝原数组的内存(直接内存拷贝速度极快);
2).查询速度快,增删速度慢。查询快是因为内存空间连续,增删速度慢是因为下标移动。
3).除了arraylist是不同步列表,它几乎替代了vector类。
(2).linkedlist:链表结构的有序列表;
1).不同步;
2).增删速度快,查询速度慢。增删速度快的原因是只需修改下链表中前后两个元素的索引指向即可;
3).能够实现堆栈(后进先出lifo,last in first out)、队列(queue,通常是fifo,first in first out)和双端队列(double ends queue)。
arraylist类的方法和list方法基本一致,所以下面介绍了list通用方法和listiterator就没必要介绍arraylist。但linkedlist比较特殊,所以独立介绍。
list接口通用方法
除了因为继承了collection而具有的通用方法外,对于list接口也有它自己的通用方法。一般list的这些通用方法针对的是序列的概念。有了序列和下标索引值,可以精确地操控某个位置的元素,包括增删改查。
(1).增:add(index,element)
(2).删:remove(index)、remove(obj)删除列表中第一个obj元素
(3).改:set(index,element)
(4).查:get(index)
(5).indexof(obj):返回列表中第一次出现obj元素的索引值,如不存在则返回-1
(6).lastindexof(obj)
(7).sublist(start,end):返回列表中从start到end(不包括end边界)中间的元素组成列表。注意返回的是list类型。
(8).listiterator():返回从头开始遍历的list类集合的迭代器listiterator。
(9).listiterator(index):返回从index位置开始遍历的list结合迭代器listiterator。
因为有了get()方法,除了iterator迭代方式,还可以使用get()方法遍历集合:
|
1
2
3
4
|
list l = new arraylist();
for (int i=0;i<l.size();i++) {
system.out.println(l.get(i));
}
|
但注意,这种方法不安全,因为l.size()是即时改变的,如果增删了元素,size()也会随之改变。
示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
import java.util.*;
public class testlist {
public static void main(string[] args) {
list ls = new arraylist();
ls.add(new student("malong1",21));
ls.add(new student("malong2",22));
ls.add(1,new student("malong3",23));
//[malong1 21,malong3 23,malong2 22]
system.out.println(ls.indexof(new student("malong3",23)));
// return:1
ls.set(2,new student("gaoxiao1",22));
//[malong1 21,malong3 23,gaoxiao1 22]
for (iterator it = l.iterator();it.hasnext();) {
//第一种迭代
student stu = (student)it.next();
if (stu.getage() == 22) {
it.remove();
// the safe way to operate element
//ls.add(new student("malong4",24)); //throw concurrentmodificationexception
}
}
//[malong1 21,malong3 23]
system.out.println(l+"\\n---------------");
for (int i=0;i<ls.size();i++) {
//第二种迭代
system.out.println(ls.get(i));
}
}
}
class student {
private string name;
private int age;
student(string name,int n) {
this.name = name;
this.age = n;
}
public string getname() {
return this.name;
}
public int getage() {
return this.age;
}
//override tostring()
public string tostring() {
return this.name + " " + this.age;
}
//override equals()
public boolean equals(object obj) {
if (this == obj) {
return true;
}
if (!(obj instanceof student)) {
throw new classcastexception("class error");
}
student stu = (student)obj;
return this.name.equals(stu.name) && this.age == stu.age;
}
}
|
上面的代码中,如果将ls.add(new student("malong4",24));的注释取消,将抛出异常,因为iterator迭代器中唯一安全操作元素的方法是iterator接口提供的remove(),而add()方法是list接口提供的,而非iterator接口的方法。但对于list集合类来说,可以使用listiterator迭代器,它提供的操作元素的方法更多,因为是迭代器提供的方法,因此它们操作元素时都是安全的。
list集合的迭代器listiterator
通过listiterator()方法可以获取listiterator迭代器。该迭代器接口提供了如下几种方法:
hasnext():是否有下一个元素
hasprevious():是否有前一个元素,用于逆向遍历
next():获取下一个元素
previour():获取前一个元素,用于逆向遍历
add(element):插入元素。注:这是迭代器提供的add(),而非list提供的add()
remove():移除next()或previous()获取到的元素。注:这是迭代器提供的remove(),而非list提供的remove()
set(element):设置next()或previour()获取到的元素。注:这是迭代器提供的set(),而非list提供的set()
例如:前文示例在iterator迭代过程中使用list的add()添加元素抛出了异常,此处改用listiterator迭代并使用listiterator提供的add()方法添加元素。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
list l = new arraylist();
l.add(new student("malong1",21));
l.add(new student("malong2",22));
l.add(1,new student("malong3",23)); //[malong1 21,malong3 23,malong2 22]
l.set(2,new student("gaoxiao1",22));//[malong1 21,malong3 23,gaoxiao1 22]
for (listiterator li = l.listiterator();li.hasnext();) {
student stu = (student)li.next();
if (stu.getage() == 22) {
//l.add(new student("malong4",24)); //throw concurrentmodificationexception
li.add(new student("malong4",24));
}
}
|
linkedlist集合
linkedlist类的数据结构是链表类的集合。它可以实现堆栈、队列和双端队列的数据结构。其实实现这些数据结构都是通过linkedlist提供的方法按照不同逻辑实现的。
提供的其中几个方法如下:因为是实现了list接口,所以除了下面的方法,还有list接口的方法可用。
addfirst(element):向链表的首部插入元素
addlast(element):向链表的尾部插入元素
getfirst():获取链表的第一个元素
getlast():获取链表最后一个元素
removefirst():移除并返回第一个元素,注意返回的是元素
removelast():移除并返回最后一个元素,注意返回的是元素
linkedlist模拟队列数据结构
队列是先进先出fifo的数据结构。封装的队列类myqueue代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
import java.util.*;
class myqueue {
private linkedlist mylist;
myqueue() {
mylist = new linkedlist();
}
// add element to queue
public void add(object obj) {
mylist.addfirst(obj);
//fisrt in
}
//get element from queue
public object get() {
return mylist.removelast();
//first out
}
//queue is null?
public boolean isnull() {
return mylist.isempty();
}
//the size of queue
public int size() {
return mylist.size();
}
//remove element in queue by index
public boolean remove(int index) {
if(this.size()-1 < index) {
throw new indexoutofboundsexception("index too large!");
}
mylist.remove(index);
return true;
}
//remove the first appearance element in queue by object
public boolean remove(object obj) {
return mylist.remove(obj);
}
public string tostring() {
return mylist.tostring();
}
}
|
操作该队列数据结构程序代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import java.util.*;
public class fifo {
public static void main(string[] args) {
myqueue mq = new myqueue();
mq.add("malong1");
mq.add("malong2");
mq.add("malong3");
mq.add("malong4"); //[malong4,malong3,malong2,malong1]
system.out.println(mq.size()); //return:4
mq.remove(2); //[malong4,malong3,malong1]
mq.remove("malong1"); //[malong4,malong3]
system.out.println(mq);
while (!mq.isnull()) {
system.out.println(mq.get());
}
}
}
|
set接口
set接口也实现了collection接口。它既然能单独成类,它和list集合的数据结构一定是大有不同的。
set接口的数据结构特性是:
1.set集合中的元素无序。这里的无序是相对于list而言的,list的有序表示有下标index的顺序,而set无需是指没有index也就没有顺序。
2.set集合中的元素不可重复。
3.因为无序,因此set集合中取出元素的方法只有一种:迭代。
4.实现set接口的两个常见类为:
(1).hashset:hash表数据结构;
1).不同步;
2).查询速度快;
3).判断元素是否重复的唯一方法是:先调用hashcode()判断对象是否相同,相同者再调用equals()方法判断内容是否相同。所以,要将元素存储到此数据结构的集合中,必须重写hashcode()和equals()。
(2).treeset:二叉树数据结构;
1).二叉树是用来排序的,因此该集合中的元素是有序的。这个有序和list的有序概念不同,此处的有序指的是存储时对元素进行排序,例如按照字母顺序,数字大小顺序等,而非index索引顺序。
2).既然要排序,而equals()方法只能判断是否相等。因此数据存储到treeset集合中时需要能够判断大小。
3).有两种方法用于构造有序的treeset集合:
a.待存储对象的类实现comparable接口并重写它的compareto()方法;
b.在构造treeset集合时指定一个比较器comparator。这个比较器需要实现comparator接口并重写compare()方法。
(3).linkedhashset:链表形式的hashset,仅在hashset上添加了链表索引。因此此类集合有序(linked)、查询速度快(hashset)。不过很少使用该集合类型。
hashset集合
hashset的用法没什么可解释的,方法都继承自set再继承自collection。需要说明的是它的无序性、不可重复性、计算hash值时的方法以及判断重复性时的方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import java.util.*;
public class testhashset {
public static void main(string[] args) {
set s = new hashset();
s.add("abcd4");
s.add("abcd1");
s.add("abcd2");
s.add("abcd3");
s.add("abcd1"); //重复
for (iterator it = s.iterator();it.hasnext();) {
object obj = it.next();
system.out.println(obj);
}
}
}
|
得到的结果是无序且元素是不可重复的:
|
1
2
3
4
|
abcd2
abcd3
abcd4
abcd1
|
这里判断字符串对象是否重复的方法是先调用string的hashcode()进行判断,如果相同,再调用string的equals()方法。其中string的hashcode()方法在计算hash值时,是根据每个字符计算的,相同字符位置处的相同字符运算结果相同。
所以上面几个字符串对象中,前缀"abcd"子串部分的hash运算结果相同,最后一个字符决定了这些字符串对象是否相同。插入时有两个"abcd1",所以总共调用了一次string的equals()方法。
如果是存储自定义的对象,如student对象,该对象定义方式如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
class student {
string name;
int age;
student(string name,int n) {
this.name = name;
this.age = n;
}
//override tostring()
public string tostring() {
return this.name + " " + this.age;
}
//override equals()
public boolean equals(object obj) {
if (this == obj) {
return true;
}
if (!(obj instanceof student)) {
return false;
}
student stu = (student)obj;
return this.name.equals(stu.name) && this.age == age;
}
}
|
即使重写了equals(),插入属性相同的student对象到hashset中时,也会认为不重复的。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import java.util.*;
public class testhashset {
public static void main(string[] args) {
set s = new hashset();
s.add(new student("malong1",21));
s.add(new student("malong1",21));
s.add(new student("malong1",21));
for (iterator it = s.iterator();it.hasnext();) {
object obj = it.next();
system.out.println(obj);
}
}
}
|
结果:
|
1
2
3
|
malong1 21
malong1 21
malong1 21
|
这是因为hastset集合的底层首先调用student的hashcode()方法,而student没有重写该方法,而是继承自object,所以每个对象的hashcode()都不相同而直接插入到集合中。
因此,需要重写student的hashcode()方法。以下是一种重写方法:
|
1
2
3
|
public int hashcode() {
return this.name.hashcode() + age*31; //31可以是任意数,但不能是1或0。
}
|
如果不加上"age*31",那么name部分的hash值有可能是相同的,但这很可能不是同一student对象,所以应该加上age属性作为计算hash值的一部分元素。但不能直接加age,因为这样会导致"new student("lisi3",23)"和"new student("lisi2",24)"的hashcode相同(3+23=2+24),因此需要为age做一些修改,例如乘一个非0和1的整数。
在student中重写hashcode()后,再插入下面这些student对象,就能相对精确地判断是否为同一个student元素。
|
1
2
3
4
5
6
7
|
s.add(new student("lisi1",21));
s.add(new student("lisi1",21)); //此处将调用equals(),且最终判断为重复对象
s.add(new student("lisi2",24));
s.add(new student("lisi3",23)); //此处将调用equals()
s.add(new student("gaoxiao1",23));
s.add(new student("gaoxiao2",21));
s.add(new student("gaoxiao3",22));
|
结果:
|
1
2
3
4
5
6
|
lisi1 21
gaoxiao1 23
gaoxiao3 22
lisi2 24
lisi3 23
gaoxiao2 21
|
linkedhashset集合
链表顺序的hashset集合,相比hashset,只需多记录一个链表索引即可,这就使得它保证了存储顺序和插入顺序相同。实现方式除了new对象时和hashset不一样,其他任何地方都是一样的。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import java.util.*;
public class testhashset {
public static void main(string[] args) {
set s = new linkedhashset();
s.add(new student("lisi1",21));
s.add(new student("lisi1",21));
s.add(new student("lisi2",24));
s.add(new student("lisi3",23));
s.add(new student("gaoxiao1",23));
s.add(new student("gaoxiao3",21));
s.add(new student("gaoxiao2",22));
for (iterator it = s.iterator();it.hasnext();) {
object obj = it.next();
system.out.println(obj);
}
}
}
|
结果:
|
1
2
3
4
5
6
|
lisi1 21
lisi2 24
lisi3 23
gaoxiao1 23
gaoxiao3 21
gaoxiao2 22
|
treeset集合
treeset集合以二叉树数据结构存储元素。二叉树保证了元素之间是排过序且相互唯一的,因此实现treeset集合最核心的地方在于对象之间的比较。
比较对象有两种方式:一是在对象类中实现comparable接口重写compareto()方法;二是定义一个专门用于对象比较的比较器,实现这个比较器的方法是实现comparator接口并重写compare()方法。其中comparable接口提供的比较方法称为自然顺序,例如字母按照字典顺序,数值按照数值大小顺序。
无论是哪种方式,每个待插入的元素都需要先转型为comparable,确定了将要存储在二叉树上的节点位置后,然后再转型为object存储到集合中。
插入string类对象。
由于string已经重写了compareto(),因此下面插入string对象到treeset集合中没有任何问题。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import java.util.*;
//
public class testtreeset {
public static void main(string[] args) {
set t = new treeset();
t.add("abcd2");
t.add("abcd11");
t.add("abcd3");
t.add("abcd1");
//t.add(23);
//t.add(21);
//t.add(21);
for (iterator it = t.iterator();it.hasnext();) {
object obj = it.next();
system.out.println(obj);
}
}
}
|
但不能将上面"t.add(23)"等取消注释,虽然integer类也重写了compareto(),但在插入这些integer类元素时,集合中已经存在string类的元素,string类的compareto()和integer的compareto()的比较方法不一样,使得这两类元素之间无法比较大小,也就无法决定数值类的元素插入到二叉树的哪个节点。
插入实现了comparable接口且重写了compareto()的自定义对象。
例如student对象,如果没有重写compareto()方法,将抛出异常,提示无法转型为comparable。
t.add(new student("malongshuai1",23));
结果:
|
1
2
3
4
5
|
exception in thread "main" java.lang.classcastexception: student cannot be cast to java.lang.comparable
at java.util.treemap.compare(unknown source)
at java.util.treemap.put(unknown source)
at java.util.treeset.add(unknown source)
at testtreeset.main(testtreeset.java:8)
|
所以,修改student重写compareto(),在重写应该考虑哪个作为主排序属性,哪个作为次要排序属性。例如以name为主排序属性,age为次排序属性。compareto()返回正数则表示大于,返回负数则表示小于,返回0则表示等于。如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
class student implements comparable {
string name;
int age;
student(string name,int n) {
this.name = name;
this.age = n;
}
public string tostring() {
return this.name + " " + this.age;
}
public int compareto(object obj) {
if (!(obj instanceof student)) {
throw new classcastexception("class cast wrong!");
}
student stu = (student)obj;
// compare name first, then age
int temp = this.name.compareto(stu.name);
return temp == 0 ? this.age - stu.age :temp;
}
}
|
于是插入student时,将根据name中的字母顺序,相同时再根据age大小顺序,最后如果都相同,则认为元素重复,不应该插入到集合中。
|
1
2
3
4
5
|
t.add(new student("malongshuai1",23));
t.add(new student("malongshuai3",21));
t.add(new student("malongshuai2",23));
t.add(new student("malongshuai1",23)); //重复
t.add(new student("malongshuai1",22));
|
结果:
|
1
2
3
4
|
malongshuai1 22
malongshuai1 23
malongshuai2 23
malongshuai3 21
|
使用比较器comparator实现排序。此时treeset的构造方法为"treeset(comparator comp)"。
当使用了比较器后,插入数据时将默认使用比较器比较元素。
比较器是一个实现了java.util.comparator接口并重写了compare()方法的类,可以根据不同比较需求,创建不同的比较器。 例如创建一个根据age作为主排序属性,name作为次排序属性的比较器sortbyage,由于这个比较器是用来比较student对象大小的,因此必须先转型为student。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import java.util.*;
//
public class sortbyage implements comparator {
public int compare(object o1,object o2) {
//cast to student first
if (!(o1 instanceof student) || !(o2 instanceof student)) {
throw new classcastexception("wrong");
}
student s1 = (student)o1;
student s2 = (student)o2;
//compare age first, then name
int temp = s1.age - s2.age;
return temp == 0 ? s1.name.compareto(s2.name) : temp;
}
}
|
指定treeset的比较器为sortbyage,并插入一些student对象:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public class testtreeset {
public static void main(string[] args) {
set t = new treeset(new sortbyage());
t.add(new student("malongshuai1",23));
t.add(new student("malongshuai3",21));
t.add(new student("malongshuai2",23));
t.add(new student("malongshuai1",23)); //重复
t.add(new student("malongshuai1",22));
for (iterator it = t.iterator();it.hasnext();) {
object obj = it.next();
system.out.println(obj);
}
}
}
|
当为treeset集合指定了比较器时,结果将先按照age顺序再按照name排序的,尽管student类中仍然重写了compareto()方法:
|
1
2
3
4
|
malongshuai3 21
malongshuai1 22
malongshuai1 23
malongshuai2 23
|
总结
以上就是本文关于集合框架(collections framework)详解及代码示例的全部内容,希望对大家有所帮助。如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
原文链接:http://www.cnblogs.com/f-ck-need-u/p/7791128.html

相关文章



- 64M VPS建站:能否支持高流量网站运行? 2025-06-10
- 64M VPS建站:怎样选择合适的域名和SSL证书? 2025-06-10
- 64M VPS建站:怎样优化以提高网站加载速度? 2025-06-10
- 64M VPS建站:是否适合初学者操作和管理? 2025-06-10
- ASP.NET自助建站系统中的用户注册和登录功能定制方法 2025-06-10