

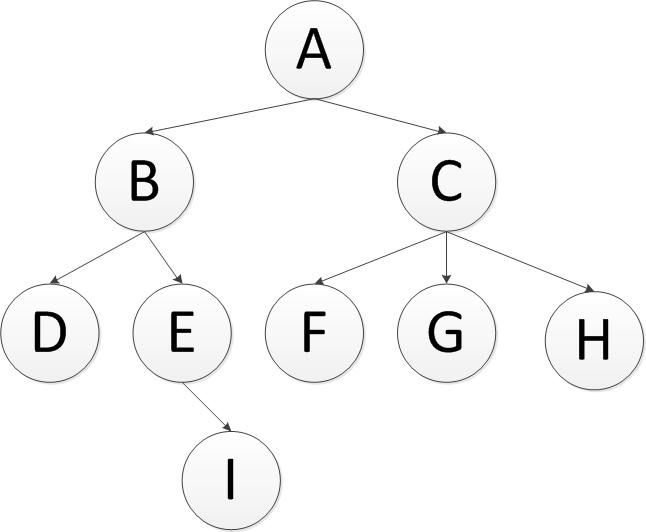
在编程生活中,我们总会遇见树性结构,这几天刚好需要对树形结构操作,就记录下自己的操作方式以及过程。现在假设有一颗这样树,(是不是二叉树都没关系,原理都是一样的)
1、深度优先
英文缩写为dfs即depth first search.
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的html文件) 。在一个html文件中,当一个超链被选择后,被链接的html文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着html文件上的超链走到不能再深入为止,然后返回到某一个html文件,再继续选择该html文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。对于上面的例子来说深度优先遍历的结果就是:a,b,d,e,i,c,f,g,h.(假设先走子节点的的左侧)。
深度优先遍历各个节点,需要使用到堆(stack)这种数据结构。stack的特点是是先进后出。整个遍历过程如下:
首先将a节点压入堆中,stack(a);
将a节点弹出,同时将a的子节点c,b压入堆中,此时b在堆的顶部,stack(b,c);
将b节点弹出,同时将b的子节点e,d压入堆中,此时d在堆的顶部,stack(d,e,c);
将d节点弹出,没有子节点压入,此时e在堆的顶部,stack(e,c);
将e节点弹出,同时将e的子节点i压入,stack(i,c);
…依次往下,最终遍历完成,java代码大概如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public void depthfirst() {
stack<map<string, object>> nodestack = new stack<map<string, object>>();
map<string, object> node = new hashmap<string, object>();
nodestack.add(node);
while (!nodestack.isempty()) {
node = nodestack.pop();
system.out.println(node);
//获得节点的子节点,对于二叉树就是获得节点的左子结点和右子节点
list<map<string, object>> children = getchildren(node);
if (children != null && !children.isempty()) {
for (map child : children) {
nodestack.push(child);
}
}
}
}
//节点使用map存放
|
2、广度优先
英文缩写为bfs即breadth firstsearch。其过程检验来说是对每一层节点依次访问,访问完一层进入下一层,而且每个节点只能访问一次。对于上面的例子来说,广度优先遍历的 结果是:a,b,c,d,e,f,g,h,i(假设每层节点从左到右访问)。
广度优先遍历各个节点,需要使用到队列(queue)这种数据结构,queue的特点是先进先出,其实也可以使用双端队列,区别就是双端队列首位都可以插入和弹出节点。整个遍历过程如下:
首先将a节点插入队列中,queue(a);
将a节点弹出,同时将a的子节点b,c插入队列中,此时b在队列首,c在队列尾部,queue(b,c);
将b节点弹出,同时将b的子节点d,e插入队列中,此时c在队列首,e在队列尾部,queue(c,d,e);
将c节点弹出,同时将c的子节点f,g,h插入队列中,此时d在队列首,h在队列尾部,queue(d,e,f,g,h);
将d节点弹出,d没有子节点,此时e在队列首,h在队列尾部,queue(e,f,g,h);
…依次往下,最终遍历完成,java代码大概如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public void breadthfirst() {
deque> nodedeque = new arraydeque>();
map node = new hashmap();
nodedeque.add(node);
while (!nodedeque.isempty()) {
node = nodedeque.peekfirst();
system.out.println(node);
//获得节点的子节点,对于二叉树就是获得节点的左子结点和右子节点
list> children = getchildren(node);
if (children != null && !children.isempty()) {
for (map child : children) {
nodedeque.add(child);
}
}
}
}
//这里使用的是双端队列,和使用queue是一样的
|
总结
以上就是本文关于深度优先与广度优先java实现代码示例的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
原文链接:https://www.cnblogs.com/toSeeMyDream/p/5816682.html

相关文章



- 64M VPS建站:能否支持高流量网站运行? 2025-06-10
- 64M VPS建站:怎样选择合适的域名和SSL证书? 2025-06-10
- 64M VPS建站:怎样优化以提高网站加载速度? 2025-06-10
- 64M VPS建站:是否适合初学者操作和管理? 2025-06-10
- ASP.NET自助建站系统中的用户注册和登录功能定制方法 2025-06-10



