前面我们已经接触过几种数据结构了,有数组、链表、hash表、红黑树(二叉查询树),今天再来看另外一种数据结构:栈。
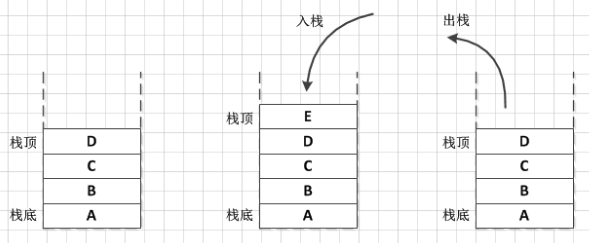
什么是栈呢,我们先看一个例子:栈就相当于一个很窄的木桶,我们往木桶里放东西,往外拿东西时会发现,我们最开始放的东西在最底部,最先拿出来的是刚刚放进去的。所以,栈就是这么一种先进后出(firstinlastout,或者叫后进先出)的容器,它只有一个口,在这个口放入元素,也在这个口取出元素。那么我们接下来学习jdk中的栈。
一、vector&stack的基本介绍和使用
我们先看下jdk种的定义:
|
1
|
public class stack<e> extends vector<e> {
|
从上面可以看到stack 是继承自于vector的,因此我们要对vector 也要有一定的认识。
vector:线程安全的动态数组
stack:继承vector,基于动态数组实现的一个线程安全的栈;
1.vector 和 stack的特点:
vector与arraylist基本是一致的,不同的是vector是线程安全的,会在可能出现线程安全的方法前面加上synchronized关键字;
vector:随机访问速度快,插入和移除性能较差(数组的特点);支持null元素;有顺序;元素可以重复;线程安全;
stack:后进先出,实现了一些栈基本操作的方法(其实并不是只能后进先出,因为继承自vector,可以有很多操作,从某种意义上来讲,不是一个栈);
2.vector 和 stack 结构:
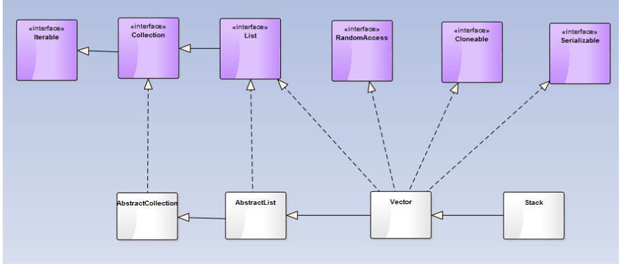
vector类
与arraylist基本一致,剩下的主要不同点如下:
1、vector是线程安全的
2、arraylist增长量和vector的增长量不一致
其它,如构造方法不一致,vector可以通过构造方法初始化capacityincrement,另外还有其它一些方法,如indexof方法,vector支持从指定位置开始搜索查找;另外,vector还有一些功能重复的冗余方法,如addelement,setelementat方法,之所以这样,是由于历史原因,像addelement方法是以前遗留的,当集合框架引进的时候,vector加入集合大家族,改成实现list接口,需要实现list接口中定义的一些方法,但是出于兼容考虑,又不能删除老的方法,所以出现了一些功能冗余的旧方法;现在已经被arraylist取代,基本很少使用,了解即可。
stack类
实现了栈的基本操作。方法如下:
|
1
|
public stack();
|
创建空栈
|
1
|
public synchronized e peek();
|
返回栈顶的值;
|
1
|
public e push(e item);
|
入栈操作;
|
1
|
public synchronized e pop();
|
出栈操作;
|
1
|
public boolean empty();
|
判断栈是否为空;
|
1
|
public synchronized int search(object o);
|
返回对象在栈中的位置;
对于上述的栈而言,我们基本只会经常用到上面的方法,虽然它继承了vector,有很多方法,但基本不会使用,而只是当做一个栈来看待。
3.基本使用
vector中的部分方法使用如下,另外vector的遍历方式跟arraylist一致,可以用foreach,迭代器,for循环遍历;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
import java.util.arrays;
import java.util.iterator;
import java.util.list;
import java.util.listiterator;
import java.util.vector;
public class test {
public static void main(string[] args) {
vector<integer> vector = new vector<integer>();
for(int i = 0; i < 10; i++){
vector.add(i);
}
//直接打印
system.out.println(vector.tostring());
//size()
system.out.println(vector.size());
//contains
system.out.println(vector.contains(2));
//iterator
iterator<integer> iterator = vector.iterator();
while(iterator.hasnext()){
system.out.print(iterator.next() + " ");
}
//toarray
object[] objarr = vector.toarray();
system.out.println("\\nobjarr:" + arrays.aslist(objarr));
integer[] intarr = vector.toarray(new integer[vector.size()]);
system.out.println("intarr:" + arrays.aslist(intarr));
//add
vector.add(5);
//remove
vector.remove(5);
system.out.println(vector);
//containsall
system.out.println(vector.containsall(arrays.aslist(5,6)));
//addall
vector.addall(arrays.aslist(555,666));
system.out.println(vector);
//removeall
vector.removeall(arrays.aslist(555,666));
system.out.println(vector);
//addall方法
vector.addall(5, arrays.aslist(666,666, 6));
system.out.println(vector);
//get方法
system.out.println(vector.get(5));
//set方法
vector.set(5, 55);
system.out.println(vector.get(5));
//add方法
vector.add(0, 555);
system.out.println(vector);
//remove方法
vector.remove(0);
system.out.println(vector);
//indexof方法
system.out.println(vector.indexof(6));
//lastindexof方法
system.out.println(vector.lastindexof(6));
//listiterator方法
listiterator<integer> listiterator = vector.listiterator();
system.out.println(listiterator.hasprevious());
//listiterator(index)方法
listiterator<integer> ilistiterator = vector.listiterator(5);
system.out.println(ilistiterator.previous());
//sublist方法
system.out.println(vector.sublist(5, 7));
//clear
vector.clear();
system.out.println(vector);
}
}
|
stack中的部分方法使用如下,因为stack继承vector,所以vector可以用的方法,stack同样可以使用,以下列出一些stack独有的方法的例子,很简单,就是栈的一些基本操作,另外stack除了vector的几种遍历方式外,还有自己独有的遍历元素的方式(利用empty方法和pop方法实现栈顶到栈底的遍历):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import java.util.stack;
public class test {
public static void main(string[] args) {
stack<integer> stack = new stack<integer>();
for(int i = 0; i < 10; i++){
stack.add(i);
}
system.out.println(stack);
system.out.println(stack.peek());
stack.push(555);
system.out.println(stack);
system.out.println(stack.pop());
system.out.println(stack);
system.out.println(stack.empty());
system.out.println(stack.search(6));
system.out.println("stack遍历:");
while(!stack.empty()){
system.out.print(stack.pop() + " ");
}
}
}
|
小节:
vector是线程安全的,但是性能较差,一般情况下使用arraylist,除非特殊需求;
如果打算用stack作为栈来使用的话,就老老实实严格按照栈的几种操作来使用,否则就是去了使用stack的意义,还不如用vector;
二、vector&stacke的结构和底层存储
|
1
2
3
|
public class vector<e>
extends abstractlist<e>
implements list<e>, randomaccess, cloneable, java.io.serializable
|
vector是list的一个实现类,其实vector也是一个基于数组实现的list容器,其功能及实现代码和arraylist基本上是一样的。那么不一样的是什么地方的,一个是数组扩容的时候,vector是*2,arraylist是*1.5+1;另一个就是vector是线程安全的,而arraylist不是,而vector线程安全的做法是在每个方法上面加了一个synchronized关键字来保证的。但是这里说一句,vector已经不官方的(大家公认的)不被推荐使用了,正式因为其实现线程安全方式是锁定整个方法,导致的是效率不高,那么有没有更好的提到方案呢,其实也不能说有,但是还真就有那么一个,collections.synchronizedlist()
由于stack是继承和基于vector,那么简单看一下vector的一些定义和方法源码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
// 底层使用数组存储数据
protected object[] elementdata;
// 元素个数
protected int elementcount ;
// 自定义容器扩容递增大小
protected int capacityincrement ;
public vector( int initialcapacity, int capacityincrement) {
super();
// 越界检查
if (initialcapacity < 0)
throw new illegalargumentexception( "illegal capacity: " +
initialcapacity);
// 初始化数组
this.elementdata = new object[initialcapacity];
this.capacityincrement = capacityincrement;
}
// 使用synchronized关键字锁定方法,保证同一时间内只有一个线程可以操纵该方法
public synchronized boolean add(e e) {
modcount++;
// 扩容检查
ensurecapacityhelper( elementcount + 1);
elementdata[elementcount ++] = e;
return true;
}
private void ensurecapacityhelper(int mincapacity) {
// 当前元素数量
int oldcapacity = elementdata .length;
// 是否需要扩容
if (mincapacity > oldcapacity) {
object[] olddata = elementdata;
// 如果自定义了容器扩容递增大小,则按照capacityincrement进行扩容,否则按两倍进行扩容(*2)
int newcapacity = (capacityincrement > 0) ?
(oldcapacity + capacityincrement) : (oldcapacity * 2);
if (newcapacity < mincapacity) {
newcapacity = mincapacity;
}
// 数组copy
elementdata = arrays.copyof( elementdata, newcapacity);
}
}
|
vector就简单看到这里,其他方法stack如果没有调用的话就不进行分析了,不明白的可以去看arraylist源码解析。
三、主要方法分析
1.peek()——获取栈顶的对象
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
/**
* 获取栈顶的对象,但是不删除
*/
public synchronized e peek() {
// 当前容器元素个数
int len = size();
// 如果没有元素,则直接抛出异常
if (len == 0)
throw new emptystackexception();
// 调用elementat方法取出数组最后一个元素(最后一个元素在栈顶)
return elementat(len - 1);
}
/**
* 根据index索引取出该位置的元素,这个方法在vector中
*/
public synchronized e elementat(int index) {
// 越界检查
if (index >= elementcount ) {
throw new arrayindexoutofboundsexception(index + " >= " + elementcount);
}
// 直接通过数组下标获取元素
return (e)elementdata [index];
}
|
2.pop()——弹栈(出栈),获取栈顶的对象,并将该对象从容器中删除
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
/**
* 弹栈,获取并删除栈顶的对象
*/
public synchronized e pop() {
// 记录栈顶的对象
e obj;
// 当前容器元素个数
int len = size();
// 通过peek()方法获取栈顶对象
obj = peek();
// 调用removeelement方法删除栈顶对象
removeelementat(len - 1);
// 返回栈顶对象
return obj;
}
/**
* 根据index索引删除元素
*/
public synchronized void removeelementat(int index) {
modcount++;
// 越界检查
if (index >= elementcount ) {
throw new arrayindexoutofboundsexception(index + " >= " +
elementcount);
}
else if (index < 0) {
throw new arrayindexoutofboundsexception(index);
}
// 计算数组元素要移动的个数
int j = elementcount - index - 1;
if (j > 0) {
// 进行数组移动,中间删除了一个,所以将后面的元素往前移动(这里直接移动将index位置元素覆盖掉,就相当于删除了)
system. arraycopy(elementdata, index + 1, elementdata, index, j);
}
// 容器元素个数减1
elementcount--;
// 将容器最后一个元素置空(因为删除了一个元素,然后index后面的元素都向前移动了,所以最后一个就没用了 )
elementdata[elementcount ] = null; /* to let gc do its work */
}
|
3.push(e item)——压栈(入栈),将对象添加进容器并返回
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
/**
* 将对象添加进容器并返回
*/
public e push(e item) {
// 调用addelement将元素添加进容器
addelement(item);
// 返回该元素
return item;
}
/**
* 将元素添加进容器,这个方法在vector中
*/
public synchronized void addelement(e obj) {
modcount++;
// 扩容检查
ensurecapacityhelper( elementcount + 1);
// 将对象放入到数组中,元素个数+1
elementdata[elementcount ++] = obj;
}
|
4.search(object o)——返回对象在容器中的位置,栈顶为1
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
/**
* 返回对象在容器中的位置,栈顶为1
*/
public synchronized int search(object o) {
// 从数组中查找元素,从最后一次出现
int i = lastindexof(o);
// 因为栈顶算1,所以要用size()-i计算
if (i >= 0) {
return size() - i;
}
return -1;
}
|
5.empty()——容器是否为空
|
1
2
3
4
5
6
|
/**
* 检查容器是否为空
*/
public boolean empty() {
return size() == 0;
}
|
小节:
到这里stack的方法就分析完成了,由于stack最终还是基于数组的,理解起来还是很容易的(因为有了arraylist的基础啦)。
虽然jdk中stack的源码分析完了,但是这里有必要讨论下,不知道是否发现这里的stack很奇怪的现象,
(1)stack为什么是基于数组实现的呢?
我们都知道数组的特点:方便根据下标查询(随机访问),但是内存固定,且扩容效率较低。很容易想到stack用链表实现最合适的。
(2)stack为什么是继承vector的?
继承也就意味着stack继承了vector的方法,这使得stack有点不伦不类的感觉,既是list又是stack。如果非要继承vector合理的做法应该是什么:stack不继承vector,而只是在自身有一个vector的引用,聚合对不对?
唯一的解释呢,就是stack是jdk1.0出来的,那个时候jdk中的容器还没有arraylist、linkedlist等只有vector,既然已经有了vector且能实现stack的功能,那么就干吧。。。既然用链表实现stack是比较理想的,那么我们就来尝试一下吧:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
import java.util.linkedlist;
public class linkedstack<e> {
private linkedlist<e> linked ;
public linkedstack() {
this.linked = new linkedlist<e>();
}
public e push(e item) {
this.linked .addfirst(item);
return item;
}
public e pop() {
if (this.linked.isempty()) {
return null;
}
return this.linked.removefirst();
}
public e peek() {
if (this.linked.isempty()) {
return null;
}
return this.linked.getfirst();
}
public int search(e item) {
int i = this.linked.indexof(item);
return i + 1;
}
public boolean empty() {
return this.linked.isempty();
}
}
|
这里使用的linkedlist实现的stack,记得在linkedlist中说过,linkedlist实现了deque接口使得它既可以作为栈(先进后出),又可以作为队列(先进先出)。
四、vector&arraylist的区别
list接口一共有三个实现类,分别是arraylist、vector和linkedlist。list用于存放多个元素,能够维护元素的次序,并且允许元素的重复。
3个具体实现类的相关区别如下:
1.arraylist是最常用的list实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要讲已经有数组的数据复制到新的存储空间中。当从arraylist的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
2.vector与arraylist一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问arraylist慢。
3.linkedlist是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了list接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
五、队列queue、双端队列deque简单了解
1、queue
在java5中新增加了java.util.queue接口,用以支持队列的常见操作。该接口扩展了java.util.collection接口。
|
1
2
|
public interface queue<e>
extends collection<e>
|
除了基本的 collection 操作外,队列还提供其他的插入、提取和检查操作。
每个方法都存在两种形式:一种抛出异常(操作失败时),另一种返回一个特殊值(null 或 false,具体取决于操作)。

队列通常(但并非一定)以 fifo(先进先出)的方式排序各个元素。不过优先级队列和 lifo 队列(或堆栈)例外,前者根据提供的比较器或元素的自然顺序对元素进行排序,后者按 lifo(后进先出)的方式对元素进行排序。
在 fifo 队列中,所有的新元素都插入队列的末尾,移除元素从队列头部移除。
queue使用时要尽量避免collection的add()和remove()方法,而是要使用offer()来加入元素,使用poll()来获取并移出元素。它们的优点是通过返回值可以判断成功与否,add()和remove()方法在失败的时候会抛出异常。如果要使用前端而不移出该元素,使用element()或者peek()方法。

offer 方法可插入一个元素,否则返回 false。这与 collection.add 方法不同,该方法只能通过抛出未经检查的异常使添加元素失败。
remove() 和 poll() 方法可移除和返回队列的头。到底从队列中移除哪个元素是队列排序策略的功能,而该策略在各种实现中是不同的。remove() 和 poll() 方法仅在队列为空时其行为有所不同:remove() 方法抛出一个异常,而 poll() 方法则返回 null。
element() 和 peek() 返回,但不移除,队列的头。
queue 实现通常不允许插入 null 元素,尽管某些实现(如 linkedlist)并不禁止插入 null。即使在允许 null 的实现中,也不应该将 null 插入到 queue 中,因为 null 也用作 poll 方法的一个特殊返回值,表明队列不包含元素。
值得注意的是linkedlist类实现了queue接口,因此我们可以把linkedlist当成queue来用。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import java.util.queue;
import java.util.linkedlist;
public class testqueue {
public static void main(string[] args) {
queue<string> queue = new linkedlist<string>();
queue.offer("hello");
queue.offer("world!");
queue.offer("你好!");
system.out.println(queue.size());
string str;
while((str=queue.poll())!=null){
system.out.print(str);
}
system.out.println();
system.out.println(queue.size());
}
}
|
2、deque
|
1
2
|
public interface deque<e>
extends queue<e>
|
一个线性 collection,支持在两端插入和移除元素。
名称 deque 是“double ended queue(双端队列)”的缩写,通常读为“deck”。
大多数 deque 实现对于它们能够包含的元素数没有固定限制,但此接口既支持有容量限制的双端队列,也支持没有固定大小限制的双端队列。

此接口定义在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。因为此接口继承了队列接口queue,所以其每种方法也存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)。
a、在将双端队列用作队列时,将得到 fifo(先进先出)行为。将元素添加到双端队列的末尾,从双端队列的开头移除元素。从 queue 接口继承的方法完全等效于 deque 方法,如下表所示:
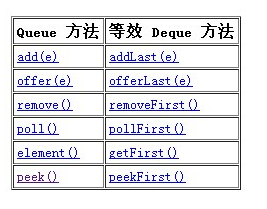
b、用作 lifo(后进先出)堆栈。应优先使用此接口而不是遗留 stack 类。在将双端队列用作堆栈时,元素被推入双端队列的开头并从双端队列开头弹出。堆栈方法完全等效于 deque 方法,如下表所示:

原文链接:http://www.cnblogs.com/pony1223/p/7940116.html

相关文章


- 64M VPS建站:是否适合初学者操作和管理? 2025-06-10
- ASP.NET自助建站系统中的用户注册和登录功能定制方法 2025-06-10
- ASP.NET自助建站系统的域名绑定与解析教程 2025-06-10
- 个人服务器网站搭建:如何选择合适的服务器提供商? 2025-06-10
- ASP.NET自助建站系统中如何实现多语言支持? 2025-06-10