一、Java爬虫——WebMagic
1.1 WebMagic总体架构图
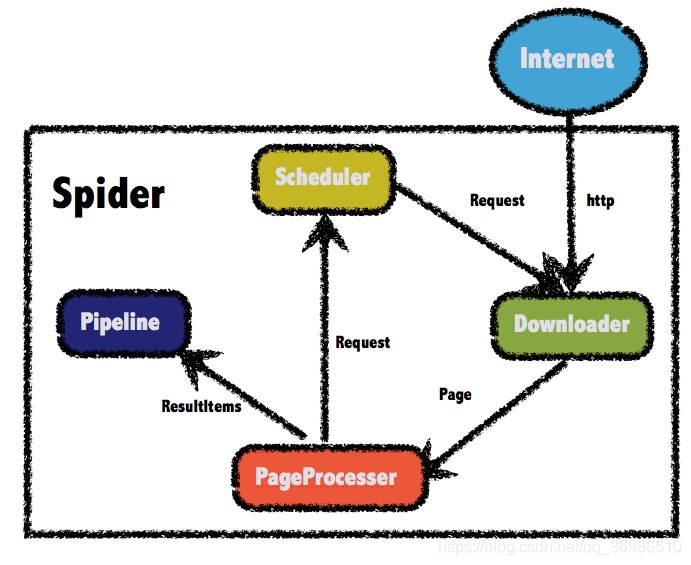
1.2 WebMagic核心组件
1.2.1 Downloader
该组件负责从互联网上下载页面。WebMagic默认使用Apache HttpClient作为下载工具。
1.2.2 PageProcessor
该组件负责解析页面,根据我们的业务进行抽取信息。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析Xpath的工具Xsoup。
1.2.3 Scheduler
该组件负责管理待抓取的URL,以及去重的工作。WebMagic默认使用JDK内存队列管理URL,通过集合进行去重。
支持使用Redis进行分布式管理。
1.2.4 Pipeline
该组件负责抽取结果的处理,包括计算、持久化到文件、数据库等等。
1.2.5 数据流转对象
1. Request
Request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。
除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。
2. Page
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。
3. ResultItems
ResultItems相当于一个Map,底层使用了LinkedHashMap进行存储,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不被Pipeline处理,跳过。
1.2.6 Spider——WebMagic核心引擎
Spider是WebMagic内部流程的核心。Downloader、PageProcessor、Scheduler、Pipeline都是Spider的一个属性,这些属性是可以自由设置的,通过设置这个属性可以实现不同的功能。Spider也是WebMagic操作的入口,它封装了爬虫的创建、启动、停止、多线程等功能。
1.3 练习Demo
需求是爬取一篇厦门限行文章,文章来源:http://xm.bendibao.com/traffic/2018116/54311.shtm,具体需求如下:
1.删除文章中超链接
2.文章中的图片下载至本地
3.删除文章末尾:温馨提示...
1.3.1 定制Downloader
为预防页面失效,定制一个Downloader,当链接地址不存在时,打印日志。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public class MyHttpClientDownloader extends HttpClientDownloader {
private Logger logger = LoggerFactory.getLogger(this.getClass());
/**
* 提示页面获取状态码
*/
@Override
protected Page handleResponse(Request request, String charset, HttpResponse httpResponse, Task task) throws IOException {
Page page = super.handleResponse(request, charset, httpResponse, task);
if(httpResponse.getStatusLine().getStatusCode()!= ConstantsField.PAGE_STATUS_200){
page.setDownloadSuccess(false);
logger.warn("页面获取状态码错误,正在重试!");
}
return page;
}
}
|
1.3.2 定制PageProcessor
该页面处理器实现了对页面的抽取,符合上面的需求。
将处理完成的数据添加进入:Page对象,并设置键分别为:imgList与content。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
public class XmPageProcessor implements PageProcessor {
/**
* 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
*/
private Site site = Site.me().setCycleRetryTimes(3).setSleepTime(1000);
/**
* 核心:编写抽取逻辑
*/
@Override
public void process(Page page) {
// 抽取页面文本数据
Selectable selectable = page.getHtml().css(ConstantsField.PAGE_CSS_CONTENT);
//处理图片
List<String> pImgList = selectable.xpath(ConstantsField.XPATH_IMG).all();
List<String> imgUrl = new ArrayList<>();
if(pImgList.size()>0){
Pattern compile = Pattern.compile(ConstantsField.REX_IMG_SRC);
for (String img : pImgList) {
Matcher matcher = compile.matcher(img);
while (matcher.find()){
imgUrl.add(matcher.group(1));
}
}
}
if(imgUrl.size()>0){
page.putField("imgList",imgUrl);
}else {
page.putField("imgList",null);
}
//对内容转换为StringBuilder
String content = selectable.toString();
StringBuilder stringBuilder = new StringBuilder(content);
//处理超链接
StringBuilder newString = dealLink(stringBuilder);
//处理末尾
int startIndex = newString.indexOf(ConstantsField.END_CONTENT);
if(startIndex>0) {
newString.delete(startIndex, stringBuilder.length());
newString.append("</div>");
}
page.putField("content",newString.toString());
}
@Override
public Site getSite() {
return site;
}
/**
* 处理超链接
*/
private static StringBuilder dealLink(StringBuilder stringBuilder){
StringBuilder newString = new StringBuilder(stringBuilder);
int aIndex = newString.indexOf("<a href");
while (aIndex != -1){
int pStart = newString.lastIndexOf("<p>", aIndex);
int pEnd = (newString.indexOf("</p>", aIndex) + 4);
newString.delete(pStart,pEnd);
aIndex = newString.indexOf("<a href");
}
return newString;
}
}
|
1.3.3 定制Pipeline
Pipeline是处理结果的地方,这里我们对结果进行存储文件的处理。网站文本存储为:stm格式,图片文本存储为其网站源文件的格式。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
public class MyFilePipeline extends FilePersistentBase implements Pipeline {
private Logger logger = LoggerFactory.getLogger(this.getClass());
private StringBuilder filepath;
private MyFilePipeline() {
this.setPath(ConstantsField.DEFAULT_SAVE_LOCATION);
}
public MyFilePipeline(String path) {
if(path!=null){
this.setPath(path);
}else {
new MyFilePipeline();
}
filepath = new StringBuilder().append(this.path).
append(PATH_SEPERATOR).append(ConstantsField.FILE_NAME)
.append(ConstantsField.FILE_POSTFIX);
}
@Override
public void process(ResultItems resultItems, Task task) {
//文件内容覆盖
try(PrintWriter printWriter = new PrintWriter(new FileWriter(getFile(filepath.toString()),false))) {
printWriter.write(resultItems.get("content").toString());
logger.info("文件生成成功,存储地址为:"+filepath);
//下载图片
List<String> imgList = resultItems.get("imgList");
if(imgList!=null&&imgList.size()>0){
boolean dowload = DownloadImgUtils.download(imgList, this.getPath());
if(dowload){
logger.info("图片下载成功,存储地址为:" + this.getPath());
}
}
} catch (IOException e) {
logger.error("输出文件出错:" + e.getCause().toString());
}
}
}
|
这里实现了网页存储为stm格式与图片存储,图片存储使用了如下工具类DownloadImgUtils:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
public class DownloadImgUtils {
/**
* 下载图片
* @param imgList 图片列表
* @param savePath 保存地址
* @return 成功返回true
*/
public static boolean download(List<String> imgList, String savePath) throws IOException {
URL url;
DataInputStream dataInputStream = null;
FileOutputStream fileOutputStream = null;
File file;
try {
for (String imgUrl : imgList) {
//截取文件名
Pattern pat=Pattern.compile(ConstantsField.REX_IMG_SUFFIX);
Matcher mc=pat.matcher(imgUrl);
while(mc.find()) {
String fileName= mc.group();
file = new File(savePath + fileName);
file.createNewFile();
fileOutputStream = new FileOutputStream(savePath + fileName);
}
url = new URL(imgUrl);
dataInputStream = new DataInputStream(url.openStream());
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length;
while ((length = dataInputStream.read(buffer))>0){
outputStream.write(buffer,0,length);
}
fileOutputStream.write(outputStream.toByteArray());
}
return true;
}catch (Exception e){
e.printStackTrace();
}finally {
dataInputStream.close();
fileOutputStream.close();
}
return false;
}
}
|
1.3.4 启动类
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public class WebMagicApplication {
private String url;
private String saveUrl;
/**
* 无参构造使用默认值
*/
public WebMagicApplication() {
this.url = ConstantsField.XM_BDB_URL;
this.saveUrl = ConstantsField.DEFAULT_SAVE_LOCATION;
}
public WebMagicApplication(String url, String saveUrl) {
this.url = url;
this.saveUrl = saveUrl;
}
public void start(){
Spider.create(new XmPageProcessor()).addUrl(this.url).addPipeline(new MyFilePipeline(this.saveUrl)).setDownloader(new MyHttpClientDownloader()).run();
}
public static void main(String[] args) {
WebMagicApplication webMagicApplication = new WebMagicApplication("http://xm.bendibao.com/traffic/2018116/5431122.shtm","C:\\\\");
webMagicApplication.start();
}
}
|
这里启动类可以使用带参构造或无参构造,无参构造默认使用URL与存储地址为ConstantsField类中的XM_BDB_URL属性和DEFAULT_SAVE_LOCATION。
练习中的ConstantsField具体如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
public final class ConstantsField {
/**
* 爬取的CSS的文本
*/
public static final String PAGE_CSS_CONTENT = "div.content";
/**
* 结束文本起始位置
*/
public static final String END_CONTENT = "<div id=\\"adInArticle\\"></div>";
/**
* 厦门本地宝URL
*/
public static final String XM_BDB_URL = "http://xm.bendibao.com/traffic/2018116/54311.shtm";
/**
* 默认文件保存地址
*/
public static final String DEFAULT_SAVE_LOCATION = "C:\\\\";
/**
* 文件名
*/
public static final String FILE_NAME = "2021厦门限行最新消息(持续更新)";
/**
* 文件后缀
*/
public static final String FILE_POSTFIX = ".stm";
/**
* 页面访问状态码
*/
public static final int PAGE_STATUS_200 = 200;
/**
* 正则匹配src
*/
public static final String REX_IMG_SRC = "src\\\\s*=\\\\s*\\"?(.*?)(\\"|>|\\\\s+)";
/**
* 正则匹配文件后缀
*/
public static final String REX_IMG_SUFFIX = "[\\\\w]+[\\\\.](jpeg|jpg|png)";
/**
* 处理图片XPATH
*/
public static final String XPATH_IMG = "//*[@id=\\"bo\\"]/*/img";
}
|
1.3.5 源码地址
练习Demo源码地址: https://gitee.com/Xiaoxinnolabi/web-magic/settings
WebMagic中文文档: http://webmagic.io/docs/zh/
WebMagic源码地址: https://github.com/code4craft/webmagic/
到此这篇关于教你如何用Java简单爬取WebMagic的文章就介绍到这了,更多相关Java爬取WebMagic内容请搜索快网idc以前的文章或继续浏览下面的相关文章希望大家以后多多支持快网idc!
原文链接:https://blog.csdn.net/qq_36986510/article/details/117782429

相关文章


- ASP.NET自助建站系统的数据库备份与恢复操作指南 2025-06-10
- 个人网站服务器域名解析设置指南:从购买到绑定全流程 2025-06-10
- 个人网站搭建:如何挑选具有弹性扩展能力的服务器? 2025-06-10
- 个人服务器网站搭建:如何选择适合自己的建站程序或框架? 2025-06-10
- 64M VPS建站:能否支持高流量网站运行? 2025-06-10